These are the opcodes for a number of miscellaneous instructions, and instruction prefixes, that remain to be discussed.
These are the additional instructions:
Opcode Modes Mnemonic Instruction ------------- -------- -------- ----------- 016x11 NM CM CPS Compose Pipeline Sequence 017x11 NM CM FLL Fixed-Length Loop 032400 NM CM SM SPC Switch Program Counter 032402 NM CM SM SPCAN Switch Program Counter After Next 032403 NM CM SM SPCIB Switch Program Counter If Branch 032406 NM CM SM SNF Switch to Normal Format 032407 NM CM SM SSF Switch to Secondary Format 0324mn NM CM SM SETAM Set Addressing Mode (m = 4,5) 0324mn NM CM SM INWM Interpret Next With Mode (m = 6,7) 140100 0000mn NM SETPW Set Primary Width (m = 0,1,2,3) 140100 0001mn NM TSETPW Temporarily Set Primary Width (m = 0,1,2,3) 140100 0002mn NM SETSW Set Secondary Width (m = 0,1,2,3) 140100 0003mn NM TSETSW Temporarily Set Secondary Width (m = 0,1,2,3) 140600 0mmmmm NM SSFUM Set Status Field Under Mask 140600 1000nn NM SVC Supervisor Call
and these are the additional instruction prefixes, which have alternate opcodes for Simple Mode in most cases:
Opcode Modes Opcode Modes Mnemonic Instruction ------ -------- ------ --------- -------- ----------- 004000 NM CM 140000 SM RMOI Register Multiple Operand Instruction 004100 NM CM 141000 SM INUAF Interpret Next Using Alternate Formats 004200 NM CM 142000 SM FCBPT Flag Conditional Branch as Preferably Taken 004300 NM CM 143000 SM FCBPNT Flag Conditional Branch as Preferably Not Taken 00mn00 NM CM 1mn000 SM OST Override Storage Type (m = 6,7) 1417i0 nnnnnn NM REP Repeat
The instruction with opcode 140600 1000nn is the Supervisor Call instruction; it causes what is essentially one of 64 software interrupts, to one of 64 destination addresses whose values are kept in a protected area in a fixed location among the lowest memory addresses.
The SETAM instruction is used to place the computer in one of sixteen possible modes which affect how instructions are interpreted. At the present time, seven modes are defined:
0000 Normal Mode 0001 Scratchpad Mode 0010 Condensed Mode 1000 Compact Mode 1001 Local Mode 1100 Simple Mode
Scratchpad mode is identical to normal mode, except that the conventional memory-reference instructions, instead of having a 4-bit opcode field followed by a three-bit destination register field, have a 1-bit opcode field followed by a six-bit destination scratchpad register field.
The opcode field is interpreted as:
0 Load 1 Store
This allows items fetched from memory to be directly placed into distinct scratchpad registers for subsequent calculation.
Compact mode allows short-format memory-reference instructions to refer to a block 1,024 bytes in length, instead of one 256 bytes in length, thus making it more feasible for a program to use short-format memory-reference instructions exclusively, or nearly exclusively.
Simple mode resolves a conflict between subdivided double operation and the alignment-based encoding used in other modes.
Opcodes of the form 000011tttt000000 are used as prefixes to instructions which store data in memory. The last four bits of the instruction indicates the tag value to apply to the word of memory to which the operand is being stored. This applies only in tagged memory mode, which is described in a later section.
The possible tag values, as described in that section, are:
0000 Executable Code 0001 Subsequent Word of Multi-Word Item 0010 Array Descriptor 0011 Character String 0100 Register Packed 0101 Register Packed Long 0110 Simple Floating 0111 Simple Floating Long 1000 Byte 1001 Halfword 1010 Integer 1011 Long 1101 Floating 1110 Double 1111 Quad
The SETPW instruction modifies the way the computer handles data memory, with mn indicating the following:
00: 32-bit word, 8-bit string character 02: 24-bit word, 6-bit string character 03: 36-bit word, 9-bit string character 04: 40-bit word, 10-bit string character 06: 60-bit word, 15-bit string character 12: 24-bit word, 8-bit string character 13: 36-bit word, 6-bit string character 14: 40-bit word, 8-bit string character 16: 60-bit word, 6-bit string character 26: 60-bit word, 10-bit string character
An explanation of how this feature works is contained in the section on the program status block; normally, this feature is only used for emulation purposes.
The SETSW instruction performs the same function for the secondary data formats, and the TSETPW and TSETSW instrucions perform the same operation as the SETPW and SETSW instructions respectively, but also indicate that the change is only intended to be in effect for a few instructions; this will affect how data, stored in the cache in the format associated with the old data memory width changed away from will be treated.
The instruction with opcode 171774 will be the SUSIUM instruction, for Set User Status Immediate Under Mask, and the next 256 bits of the instruction will indicate which bits of the rightmost 256 bits of the program status block are to be changed, and then the subsequent 256 bits of the instruction will be loaded into the corresponding bits of the program status block.
The instruction with opcode 140600 0xxxxx, the SSFUM (Set Status Field Under Mask) instruction is a general instruction for setting any portion of the program status block. Its second halfword of 16 bits consists of the following fields:
The REP instruction is similar to the repeat instructions found on the Univac 1103 computer and the Strela from the Soviet Union.
![]()
A 16-bit field indicates the number of times the subsequent instruction is to be repeated; the last three bits of the instruction increment the source, operand (if applicable) and destination addresses.
This increment is internal, and does not require the instruction to be indexed, or alter the contents of the index registers or other registers.
The increment is always in terms of the full size of the operand.
Register addresses may be incremented. If used with a long vector instruction, an increment always proceeds past 64 elements of the operand type, and it can also proceed from one long vector register to the next, or one long vector scratchpad register to the next (each of which consists of 64 scalar registers).
One of the significant benefits of this instruction is that it allows any pipelining features present in an implementation to be used with any instruction in order to vectorize it. Thus, a requirement for this instruction to function correctly is that each of the iterations of the repetition is logically independent; source and destination vectors must not overlap, for example.
As it may be possible to overlap more than one instruction in fully-pipelined vectorized mode, the CPS (Compose Pipeline Sequence) instruction is also provided.
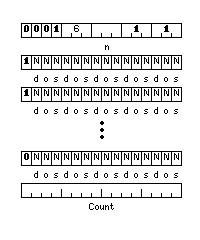
After the first halfword with the opcode, the next one contains the count of the number of repetitions to be performed. Then, there are a series of three-bit fields, indicating if the destination, operand, and/or source addresses of each of the instructions in the sequence are to be incremented on each iteration, as with the REP instruction. These are contained in a series of halfwords which begin with zero, and which each contain five such fields, if required, and finally one halfword beginning with a one, containing four such fields, and a three-bit field indicating how many, from zero to four, of them are used. Then, the instruction is followed by as many instructions to include in the pipeline sequence as are indicated by the number of these fields which are present and indicated as being used.
A normal loop construct would be sufficient to cause consecutive instructions in a program to overlap in the pipeline, so that, as long as issues such as logical dependencies do not prevent it, one instruction is issued per cycle. This special instruction is intended to allow an even denser usage of the computer's arithmetic-logic units to be specified.
Each instruction within a pipeline sequence defined with a CPS instruction is to be issued once per cycle, following the first time it is issued.
This means that all the instructions in that sequence may reach their execute phases simultaneously, although for different iterations of the sequence.
Therefore, no two instructions in a sequence formed with a CPS instruction can use the same portion of the same ALU, where the portions into which an ALU is divided are:
thus, the CPS instruction can only be used to compose fairly simple vector operations, such as a multiply-and-accumulate. However, an operation on a floating-point vector and one on a similar fixed-point vector can be interleaved, and extended operate instructions can also be included in a sequence (one only of each type).
Short vector instructions can be included in a sequence, but the short vector ALU is not divided into parts.
Simple floating multiplication and division instructions also use the addition portion of the integer ALU in addition to the multiplication or division portion.
Normally, long vector instructions cannot be part of the sequence composed by a CPS instruction, as they are usually performed by pipelining the operations on the consecutive elements of a vector in a single ALU. However, in the case of a high-performance implementation of the architecture, which provides a set of sixty-four arithmetic-logic units to handle all the elements of a long vector in parallel, and which therefore may also provide the cache-internal parallel computing feature, the CPS instruction can be applied to such instructions, allowing the maximum possible performance to be obtained from the computer. Multi-way long vector instructions are always treated as using all portions of the ALU used for the data type.
There can be no logical dependencies between instructions in one iteration of a CPS sequence and a subsequent iteration, and subsequent iterations cannot use the same resources in any way that can lead to interference as these iterations execute concurrently with a delay of only one cycle between them. One consequence of these restrictions is that operands whose location is not incremented can only be used as constants, never as working registers or working storage. Values can be stored in register or memory operands whose location is incremented, on the assumption that they will not be read back in during the execution of the complete CPS sequence; if this assumption is not true, the values read back in will be unpredictable.
The first occurrence of a given instruction in a CPS sequence, however, may be delayed by more than one cycle from the first occurrence of the immediately preceding instruction. Thus, subject to the restriction above on the use of resources, logical dependencies are permitted between one instruction and subsequent instructions in the same iteration of the sequence.
One way subsequent instructions in the same CPS sequence can work on the same data without having subsequent iterations use the same resources would be to store the intermediate results in vectors in memory. To avoid forcing the unnecessary use of memory for intermediate results, when register 0 of any group of registers (including the vector registers and the vector scratchpad) is a non-incremented operand of an instruction, the actual register 0 is not used, and instead this references an intermediate result passed from one instruction to the next in the pipeline. Thus, storage of values in register 0 as a non-incremented operand is allowed.
Again, because the next repetition of the group of instructions forming the pipeline sequence is intended to begin before the previous repetition has ended, actual registers cannot be used for intermediate results. While the actual register 0 could only contain one value at a time, iterations proceeding concurrently in different stages would be, at any given time, using a register address of 0 to stand for different and independent portions of the arithmetic unit.
One important limitation of the use of register 0 in this fashion is that a value stored in temporary storage using register address 0 can only be read back in by the immediately following instruction in a given iteration of a pipeline sequence.
Note that when determining the number of instructions that are affected by a CPS instruction, the INUAF, INWM, and the supplementary instruction prefix are not counted as separate instructions, but as part of the instruction that follows them.
Also, string and packed decimal instructions cannot be used with REP or CPS, but register packed instructions can be.
The FLL instruction is similar in form to the CPS instruction, but does not have any of its restrictions. The additional field consisting of the least significant three bits in the first sixteen bits of the instruction, if they are nonzero, indicates which of the arithmetic/index registers, when its contents are read by an instruction inside the loop, will instead stand for the loop counter, which will start with 0 and increase by 1 for each iteration of the loop. If that field contains zero, the loop counter will not be accessible within the loop. The FLL instruction may contain any other instruction, and may even be nested. Its purpose is to make it simple for the instruction issuer to produce the same sequence of micro-operations for a loop as it would produce if the loop had been unrolled, without the need to fetch additional instructions or consume memory storing them. Note that if all loop counters must be accessible, the FLL instruction would not be able to be nested more than seven deep.
A limit to nesting FLL instructions, however, is clearly required, to allow the complexity of the instruction issuer to be bounded. Allowing a maximum of sixteen levels of nesting appears to be sufficiently generous. Note that interrupts can occur after the individual instructions under the control of an FLL instruction; when this happens, side information is contained in the model-dependent portion of the machine state. The issuing of micro-operations called for by FLL sequences can be terminated by flushing the thread to which they belong from execution.
The RMOI instruction modifies normal instructions, and vector instructions as used in the vector register mode, so that their arguments contain multiple operands. This causes these normal instructions to function in a way that is strongly analogous to short vector instructions, except that the short vectors are now 32 bits in length (for integer operations) or 64 bits in length (for floating-point operatons).
Instructions involving a floating-point destination register of any kind, including the various floating-point vector registers, when modified with the RMOI prefix, always take a 128-bit argument; this argument may contain a pair of 64-bit double precision floating point numbers if a double-precision instruction is modified, four 32-bit single precision floating point numbers if a single-precision instruction is modified, and eight 16-bit short floating point numbers, as used with the short vector instructions, if a medium precision instruction is modified.
Instructions involving one of the arithmetic/index registers as their destination register, when modified with the RMOI prefix, take a 32-bit argument; those using one of the fixed-point supplementary registers as their destination register (or the entire group of fixed-point supplementary registers as the fixed-point vector accumulator, or a fixed-point vector register or a location in the fixed-point vector scratchpad) take a 64-bit argument. The type of the instruction being modified determines whether the argument is divided into four or eight 8-bit bytes, two or four 16-bit halfwords, or, in the case of 64-bit arguments only, two 32-bit words.
It is expected that implementations will, when the RMOI prefix is used, start the arithmetic operations on the successive components of the operands on successive clock cycles; the primary benefit of the RMOI prefix is simply to conserve register space, and provide an additional means of performing operations compatible with short vector operations. Additional speed will still be obtained by permitting more operations to be specified as pipelined at one time; also, in the trivial case of fixed-point addition and subtraction, partitioning the arithmetic units may only require minimal additional circuitry, and thus the operations may be performed in parallel in this case. As with short vector floating-point operations, the values stored in registers between operations will not contain any guard bits.
The SPC, SPCAN, and SPCIB instructions are used with the Bisequential Operation feature of the computer, particularly when the computer is in suspended bisequential mode. In this mode, programs can switch between using one of two different program counters to fetch the next instruction. This lets two processes which are closely interlocked run with arbitrary concurrency with low overhead. The SPC instruction immediately toggles which program counter is being used; the SPCAN instruction causes the toggle to take place after the next instruction, which could be a jump instruction (note that when this mode is enabled, changeover to the auxilliary program counter must first be done in association with a jump instruction to initialize that program counter); and the SPCIB instruction is used preceding a conditional branch instruction, and causes a change in the program counter used only if the branch is taken. Used with a non-branch instruction, it has no effect; used with an unconditional branch, it toggles the program counter.
The INUAF instruction is used to facilitate conversion from one data format to another; the instruction it precedes uses the integer and floating-point formats, and the data width, and the endian conventions, indicated by the bits in the Program Status Block giving secondary formats. Note that as the format of the internal contents of floating-point registers may depend on the floating-point format in use, conversions from the alternate format in memory and the current standard format in the registers accompany any instruction so prefixed where necessary.
Note that if operand filtering, as described in the section on code 12 microprograms, is in effect, it is in effect only for the normal format, not the secondary format.
When the computer is in suspended dual-format mode, the SNF and SSF instructions are also available to switch between using the normal format and the secondary format.
The FCBPT and FCBPNT instructions act as no-operation instructions as far as the action to be performed by a program is concerned, but their purpose, when placed before a conditional-branch instruction, is to indicate whether that conditional branch instruction will be taken in most cases (as for the instruction that repeats a loop) or will not be taken in most cases. This allows the efficiency of branch prediction to be improved.
As we have previously seen, the opcodes of the form 00xx00 and 01xx00 are reserved for use as prefixes to other instructions, the length of which is decoded normally. In addition, two-halfword prefixes have the form 141xx0 xxxxxx so as to allow more efficient encoding of a wider range of prefixes.
The prefixes with opcodes in the range of 000000 to 003700 are used to extend the opcodes of some subsequent instructions so that their effective opcode is ten bits long; we have seen these on earlier pages: some of them are used to specify additional operations, but their usual use is to allow operations on special datatypes such as compressed decimal and simple floating.
Prefixes in the range 141000 xxxxxx to 141370 xxxxxx specify modified instructions associated with these same datatypes; we have encountered them as prefixing the targeted arithmetic instructions for decimal exponent floating-point and register compressed decimal floatng point.
On this page, we have seen that the Repeat instruction is considered a prefix, having the form 1417n0 xxxxxx.
As noted above, both the short vector instructions and the extended translate instructions will be described in their own sections.