For high-speed vector operations, a full implementation of the architecture is endowed with a set of 64 integer ALUs and a set of 64 floating-point ALUs. To permit them to be used for superscalar processing as well, each ALU is provided with an L1 cache. To build on these elements with as little additional circuitry as possible to create 64 processors capable of operating independently, giving each processor its own register file in addition to the L1 cache was avoided, permitting a very simple and regular instruction format, which is shown below:
![]()
The first 128 of the eight-bit opcodes defined for use by the sixty-four small processors which handle this simple two-address memory-to-memory instruction set are as follows:
00000 00001 00010 00011 00100 00101 00110 00111
MVB IB MVH IH MV I MVL 000
CB UCB CH UCH C UC CL UCL 001
LIB ULB LIH ULH LI UL LIL 010
STIB XB STIH XH STI X STIL XL 011
AB NB AH NH A N AL NL 100
SB OB SH OH S O SL OL 101
MB MEB MH MEH M ME ML MEL 110
DB DEB DH DEH D DE DL DEL 111
01000 01001 01010 01011 01100 01101 01110 01111
LSBU MVF MEU MVD MEUD MVQ MEUQ 000
CF DEU CD DEUD CQ DEUQ 001
LSBSM LIF LID LIQ 010
CCN STIF STID STIQ 011
LDBU AF AU AD AUD AQ AUQ 100
SF SU SD SUD SQ SUQ 101
LDBSM MF MU MD MUQ MQ MUQ 110
CCT DF DU DD DUD DQ DUQ 111
As there are no registers, the swap instructions have been removed; as there are therefore no index registers, a Load Indirect instruction and a Store Indirect instruction have been added. These instructions take a halfword value as a source argument, which then points to the value used as the source argument of the load or store. Also, as the instructions are memory-to-memory instructions, the regular load and store instructions are replaced by a Move instruction.
The CCN and CCT instructions, although their opcodes are in the same region as those used for standard memory-reference operations, belong to a different group that will be described later.
The quadruple-precision floating-point instructions shown here may not necessarily be provided. While it is useful to have 128-bit floating-point arithmetic available, this is a luxury feature, not a basic one, that would likely see only limited use even in the applications that do require it. Thus, 128-bit floating-point may be provided in the main ALU, and in the ALU for short vector operations, but not in the bank of sixty-four ALUs used to accelerate long vector operations.
Note, however, that this does not mean that long vector quad-precision floating point instructions would also be omitted. The original Cray computers with operations similar to the long vector instructions, although they had groups of 64 registers, did not have groups of 64 ALUs, they instead relied on a single pipelined ALU. Of course, this would mean that long vector operations on quadruple precision values would no longer be comparable in speed to long vector operations on double precision values.
The conditional jump instructions are:
C1000xxx JL Jump if Low C2000xxx JE Jump if Equal C3000xxx JLE Jump if Low or Equal C4000xxx JH Jump if High C5000xxx JNE Jump if Not Equal C6000xxx JHE Jump if High or Equal C7000xxx JNV Jump if No Overflow C8000xxx JV Jump if Overflow CA000xxx JC Jump if Carry CB000xxx JNC Jump if No Carry CF000xxx JMP Jump
here noted in hexadecimal form rather than octal form, due to the arrangement of the internal instructions.
As well, a subroutine jump instruction, and a jump indirect instruction, useful for returning from a subroutine, are provided:
C0rrrxxx JSB Jump to Subroutine CE000xxx JI Jump Indirect
The Jump to Subroutine instruction transfers control to the location which is its source operand, and stores the return address in the halfword which is its destination operand. The Jump Indirect instruction finds the address to which to transfer control in the halfword that is its source operand.
The shift instructions are:
E00nnxxx SHLB Shift Left Byte E10nnxxx SHRB Shift Right Byte E30nnxxx ASRB Arithmetic Shift Right Byte E40nnxxx ROLB Rotate Left Byte E50nnxxx RORB Rotate Right Byte E60nnxxx RLCB Rotate Left through Carry Byte E70nnxxx RRCB Rotate Right through Carry Byte E80nnxxx SHLH Shift Left Halfword E90nnxxx SHRH Shift Right Halfword EB0nnxxx ASRH Arithmetic Shift Right Halfword EC0nnxxx ROLH Rotate Left Halfword ED0nnxxx RORH Rotate Right Halfword EE0nnxxx RLCH Rotate Left through Carry Halfword EF0nnxxx RRCH Rotate Right through Carry Halfword F00nnxxx SHL Shift Left F10nnxxx SHR Shift Right F30nnxxx ASR Arithmetic Shift Right F40nnxxx ROL Rotate Left F50nnxxx ROR Rotate Right F60nnxxx RLC Rotate Left through Carry F70nnxxx RRC Rotate Right through Carry F80nnxxx SHLL Shift Left Long F90nnxxx SHRL Shift Right Long FB0nnxxx ASRL Arithmetic Shift Right Long FC0nnxxx ROLL Rotate Left Long FD0nnxxx RORL Rotate Right Long FE0nnxxx RLCL Rotate Left through Carry Long FF0nnxxx RRCL Rotate Right through Carry Long
The shift count is placed in the source address field, the memory location whose contents are to be shifted is identified in the destination address field.
A family of functions relevant to parallel computation, is added, the Transmit/Receive functions. These functions use a family of sixteen buses, each 128 bits in width, that interconnect the sixty-four long vector arithmetic-logic units. (Although each ALU is connected to sixteen buses, the total number of buses involved is actually 128, as each bus only interconnects eight of the sixty-four processors.)
The instructions are:
D0xxxb00 RCB Receive Byte D1xxxb00 TXB Transmit Byte D2xxxb00 RCH Receive Halfword D3xxxb00 TXH Transmit Halfword D4xxxb00 RC Receive D5xxxb00 TX Transmit D6xxxb00 RCL Receive Long D7xxxb00 TXL Transmit Long DAxxxb00 RCF Receive Floating DBxxxb00 TXF Transmit Floating DCxxxb00 RCD Receive Double DDxxxb00 TXD Transmit Double DExxxb00 RCQ Receive Quad DFxxxb00 TXQ Transmit Quad
The transmit instructions take the value from the destination location, and place it on the processor's own bus line, either in the long-range bus, if the first bit of the source address field is a 1, or the short-range bus, if the first bit of the source address field is zero. This value remains available to other processors until another transmit instruction to the appropriate bus is issued, or until the processor exits from the current cache-internal parallel computation.
The receive instructions take a value from the bus whose number is given in the last three bits of the instruction, either among the long-range buses, if the first bit of the source address field is a 1, or among the short-range buses, if the first bit of the source address field is a zero. If no value is being transmitted, the value in the target register is unchanged, and the instruction sets the zero condition code; otherwise, it clears this code, so a conditional branch can be used to determine if a value has been received.
The sixty-four processors, numbered from 0 to 63, if their octal number is mn, communicate with processors whose number is of the form xn along the long-range buses, and of the form mx along the short-range buses, and in both cases, x is the three bit number of the bus specified in the instruction. Thus, processor mn transmits data to processors with numbers of the form xn along the long-range bus m to which they are connected, and to processors of the form mx along the long-range bus n to which they are connected.
The following diagram may make this arrangement easier to understand:

Note that each of the buses shown in the diagram is intended to appear to the programmer as a 128-bit-wide data bus. This may be impractical, and instead the buses may be only a single bit wide, with data transmitted serially along them. Because such an operation as a floating-point divide requires the equivalent of a large number of gate delays to be accomplished, it is possible this can be done without too severe a performance penalty.
This type of bus is required to permit rapid handling of long vector operands which are not necessarily in the same alignment in memory, by allowing an arbitrary shift along the array of processors in at most two steps, and thus making it available for cache-internal parallel computation as well increases its power.
The way in which this type of bus is used for the purpose of facilitating long vector operations is illustrated as follows:
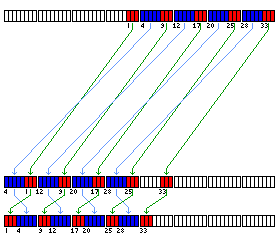
An array of numbers beginning at an arbitrary point, shown by the red and blue rectangles in the top row, is brought to alignment with the beginning of the processor array first by having its elements moved by a multiple of eight units, to form the middle row. Note that the elements marked in blue are moved an extra eight units forwards. Then, the vector is brought to complete alignment through a rotation that takes place within each group of eight units, changing from the arrangement in the middle row to the fully aligned positioning in the bottom row.
Of course, that purpose can be achieved through somewhat simpler circuitry that would not be suitable for the type of interprocessor communications envisaged; for example, a circuit that routed words in a manner similar to that in which a barrel shifter routes bits, first between groups of eight words, and then within each group of eight words.
The instruction format does not provide space for specifying the use of index registers. The following four instructions provide an alternative means of addressing array elements without resorting to self-modifying code:
48000xxx LSBU Load Source B Unmodifiable 4A000xxx LSBSM Load Source B Source Modifiable 4C000xxx LDBU Load Destination B Unmodifiable 4E000xxx LDBSM Load Destination B Source Modifiable
These instructions load the source and destination B registers from their least significant 12 bits of their 16-bit source arguments. For any other instructions, if either or both of the source B and destination B registers are set, their contents are added to the source and destination fields of those instructions before execution, and then they are cleared.
In the case of the LSBU and LDBU instructions, when they execute, if either or both of the B registers are set, they are ignored; in the case of the LSBSM and LDBSM instructions, the source B register modifies the instruction normally, but the destination B register is ignored.
This allows instructions to be set up that have both source and destination arguments indexed with values which are themselves chosen by means of an index, For example,
A(IX(IXX)) = A(IX(IXX)) + B(IY(IYY))
can be expressed as:
LSBU IXX
LDBSM IX
LSBU IYY
LSBSM IY
AF A,B
which sets up the destination B register first, as the source B register can be loaded from an indexed location without disturbing the destination B register.
Note that the B register contents do not affect the opcode of an instruction. This feature, although significantly different in detail, can be traced back in its inspiration to the Elliott 803 computer and its predecessors, such as the Ferranti Mark I, from which the British term "B-line" for an index register originated.
With the exception of constructs for two-level indexing such as depicted in the example above, the use of these instructions can be made more understandable for programmers used to conventional index registers by thinking of these instructions as instruction prefixes used to indicate indexing.
As well, two other instructions need to be defined in addition:
43000000 CCN Conclude and Notify 47000000 CCT Conclude and Terminate
These are halt instructions; the CN instruction indicates that one of the 64 processes has finished its work; the CT instruction indicates that one of the processes has found what all the processes were looking for, and thus all 64 processes are to be stopped forthwith.