As noted in the previous section, the memory used by the 64 on-chip RISC processors will not be located in the main, or Level 2, on-chip cache memory, but in the Level 1 cache memory local to each ALU that is required to facilitate superscalar operation. This memory may be 4,096 bytes in size, but the formats of these instructions allow for up to 64K bytes to be used with each processor.
Instructions will be required to initiate MIMD parallel computations, and to transfer data to and from the individual processors.
The instructions of this type do four things:
Additionally, instructions are required to start a parallel process executing, and, after it concludes, to either restart it, or free up the resources it has allocated to it.
These setup instructions are defined as being among the operate instructions of the computer, but instead of being defined for all modes in the manner in which the somewhat analogous define extended translate and execute extended translate instructions are defined, because of the amount of opcode space they require, and because these operations involve the long vector registers, they are defined only within the version of the operate instructions used in the various long vector modes.
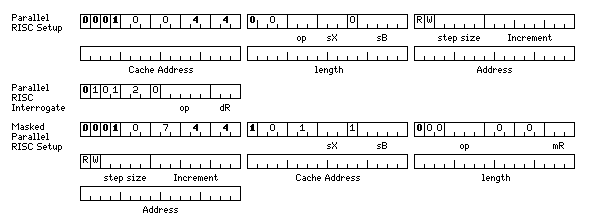
The format of these instructions is shown below:
Note that the base register field is five bits long, as in this mode the scratchpad registers, the scratchpad pointer registers, and the scratchpad array registers all serve as additional base registers.
These instructions are accessible from Normal Mode and Compact Mode. From Simple Mode, the Parallel RISC Interrogate instructions stay the same, the Parallel RISC Setup instructions begin with 040440 instead of 010044, and the Masked Parallel RISC Setup instructions begin with 047440 instead of 010744.
The possible values of the opcode field indicate these instructions:
000 DFS Define Stepped 001 DFI Define Interleaved 010 DFM Define Multiple 100 DFSX Define Stepped and Execute 101 DFIX Define Interleaved and Execute
In the Define Stepped instruction and the Define Stepped and Execute instruction, all the fields shown in the illustration above are used. The source index, base, and address specify the starting location of the main memory area mapped to the cache memory used by the first RISC processor at the address specified by the cache address field.
The bits marked R and W indicate the relationship between this cache and main memory; if R is set, memory is copied into cache before starting, and if W is set, cache is copied back into memory when calculations complete. A correspondence may be defined with either or both of these bits set.
The increment between the start of the block used for one RISC processor and the next is determined by taking the binary number in the Increment field, and appending to it the number of trailing zeroes, from 0 to 31, indicated by the number in the step size field. This allows a very large expanse of memory to be spanned, although not an entire virtual memory space with a 64-bit address.
In the Define Interleaved instruction and the Define Interleaved and Execute instruction, the correspondence is instead between all 64 RISC processor memories and one contiguous block of main memory. Each group of 64 items in memory is allocated one to a processor.
For this instruction, the R and W bits of the third halfword are used, and the step size indicates the size of an item in memory:
0000 one byte 8 bits 0001 two bytes 16 bits 0010 four bytes 32 bits 0011 eight bytes 64 bits 0100 sixteen bytes 128 bits 0101 thirty-two bytes 256 bits 0110 sixty-four bytes 512 bits
and so on.
The Define Multiple instruction always defines a correspondence of a read-only nature. It causes the same area of main memory to be mapped to the given location within the local cache memory of each of the 64 RISC processors. Thus, the third halfword is not divided into fields; instead, it specifies the initial program counter value to be used by all 64 RISC processors.
In addition to defining correspondences between main memory and RISC processor caches, the Define Stepped and Execute instruction and the Define Interleaved and Execute instruction begin the execution of a parallel program. There is no Define Multiple and Execute instruction, since there is no point in starting 64 processors in parallel executing the same program unless there is some distinguishing factor present to cause each one to contribute additional results.
The opcodes of 6 and 7 are used to allow additional operations to be performed.
With an opcode of 6, we have the format used for an instruction that queries the status of the 64 RISC processors.
00000 IG Interrogate 00001 TPPC Test for Parallel Process Complete
The Interrogate instruction places in the register pair indicated by the dR field a vector indicating, by a 1 bit, which of the processors have indicated, by executing a CCN instruction, that it has finished its work. If any process has executed a CCT instruction, the register pair will be filled with 64 ones.
The Test for Parallel Process Complete sets the condition codes as if a calculation produced zero if an Interrogate instruction would produce an all-zero result, as if a calculation produced a negative number if an Interrogate instruction would produce an all-ones result, and as if a calculation produced a positive number in any other case. The dR field is not used, and should be zero.
With an opcode of 7, we have instructions that make use of the output of an Interrogate instruction to permit more continuous use of the 64 RISC processors in the case where the time which they take to perform their operations is highly variable.
0000 DFSM Define Stepped under Mask 0001 PIM Promote Interleaved under Mask 0010 DFMM Define Multiple under Mask 0100 DFSMX Define Stepped under Mask and Execute 0101 PIMX Promote Interleaved under Mask and Execute
Here, the mR field indicates a register pair, containing 1 bits indicating to which RISC processors the correspondence being defined applies; the other RISC processors are not to be disturbed. The dR field is not used for these instructions, and should be zero.
In the case of the Define Stepped instructions of this type, the increment is added from one processor that is used to the next; the processors that are not used do not cause any main memory to be skipped.
A Promote Interleaved under Mask instruction does not change the sequence in which different processors are allocated to elements of a group of 64 elements in memory. Instead, it advances the selected processors to the corresponding elements of the next area in memory. This works best when variations in the time taken by different processors will average out over the complete task. The step size and length fields in this instruction are required, and need to be the same as those in the original Define Interleaved instruction, but the Address and Cache Address fields are not used in this instruction, and are omitted.