A simple form of pipelined execution, which can be implemented without too much overhead and complexity, was present even on early high-performance computers; in this connection, by "early", I mean computers implemented with discrete transistors. The computers which exhibited this simple form of pipelining typically divided the performance of an instruction into three phases: fetch, decode, and execute. Retrieving an instruction from memory, and determining what operations it calls for, are clearly independent of anything connected to any other instruction (with the one exception, of course, of a preceding instruction that branches, so that the instruction in question will never be executed). (Some computers that I include in this simple class of pipelining only overlapped fetch and execute, with decode included as part of the execute phase; the Zilog Z-80 microprocessor belongs to that category.)
Unlike the situation on today's microprocessors, as the speed at which memory operated was comparable to that of the logic in the CPU, and as the operation in the execution phase could just be a simple fixed-point add, it was possible that these three phases could be equal in size, so that the execute phase of one instruction would overlap with the decode phase of the next one, and the fetch phase of the instruction after that. Of course, other instructions would take multiple cycles to execute, such as multiplication and division, and that would create a period in which the fetch and decode units were idle.
At the time, this was thought of as the normal case of pipelined operation, while today this is often called overlapped operation, to distinguish it from genuine pipelining (which was then called superpipelined operation).
A few examples of computers with this level of pipelining include the UNIVAC LARC, the IBM 7094 II, the Ferranti Atlas, the Ferranti Atlas II, the SDS 9300, the IBM 360/75, the IBM 360/85, the IBM 370/165... and, much later, the Zilog Z-80 microprocessor.
Pipelining in the modern sense involves breaking up the execute phase of an instruction into multiple steps, so that different stages of the ALU may all be kept busy at once.
This involves a different design of the ALU; on simpler computers, the ALU was basically just a parallel adder, with additional circuits to allow it to perform logical operations like AND, OR, and XOR, and a secondary accumulator, often called the multiplier-quotient register, to perform much the same function as the similarly-named component of a mechanical adding machine: to contain one of the operands, and provide temporary storage, to facilitate multiplication and division. Since in that case, the multiple steps of a multiplication or division would all use the same logic circuits, the next such operation would have to wait until the previous one was finished.
However, on a previous page in this section, we have already met circuits such as Sklansky adders and Wallace Tree multipliers that, in addition to providing high performance, involve logic which can be strung out in a straight line from the beginning to the end of the operation.
In order to break such circuits up, so that the successive stages of multiple operations can take place one after the other without interference, with each result being properly retrieved when expected, buffers need to be inserted after each cycle's worth of logic. A circuit known as the Earle Latch (named after an engineer at IBM) allowed the delays this might potentially introduce to be eliminated in most cases.
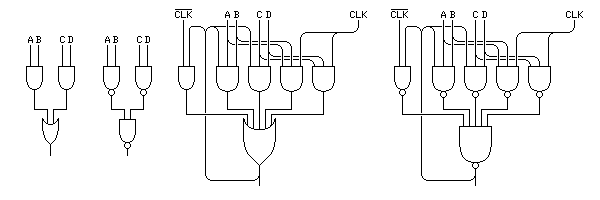
Many common logic circuits have as their final stage a group of AND gates followed by an OR gate that combines their outputs. In the image above, an example of such a circuit is shown, first in its conceptual form, and then in the form in which it is likely to actually be implemented, entirely from NAND gates, with the signals in the middle layer inverted.
Then, in the two diagrams on the right of the image, the corresponding Earle latch is shown. In addition to having the same four inputs as the original sum of products circuit, it also has a clock signal and its complement as inputs.
When the clock is 0, the output of the Earle latch is gated back to itself, by the first of the five AND gates in the top layer.
When the clock is 1, the latch is filled with a new value, as gated in by the last two of the AND gates in the top layer.
In addition, because of the possibility of clock skew, the second and third of the AND gates are controlled not by a clock signal, but by the output of the latch, so that if the old and new values are both 1, clock skew will not cause the latch to be set to zero by accident.
Thus, the Earle latch, if replacing two input gates by three-input and five-input gates does not increase delay, causes a delay of two gate times, the same as that of the circuit which it replaces.
As noted above, when the Execute phase of dealing with an instruction is split into parts, to be overlapped with parts of the Execute phases of other instructions, there are things to watch out for.
One kind of problem is called a structural hazard; the instructions attempted to be executed at the same time would use the same ALU resource. Even when the various ALUs in the processor are all designed to work well with pipelining (this is not a given; in many real systems, division, for example, still involves looping within the ALU, to save costs for what is considered a rare operation), so that two instructions started on different cycles always use different stages of the ALU, something that delays one instruction for even just a cycle can create conflicts.
Another obvious potential problem is a branch hazard; until a conditional branch instruction finishes executing, one does not really know which instruction is to be executed next. Many computers maintain small internal tables intended to indicate which result of a conditional branch is most likely, and then attempt (speculatively) to begin processing the instructions down that path, reserving the ability to abandon them if the guess proves not to be correct.
Perhaps the most serious problem, though, is posed by the various data hazards. If an assembly-language program is written by hand, particularly if it was written for a non-pipelined implementation of a given instruction set architecture (ISA), it is quite common and likely for it to be written in the most simple and obvious way: if several operations are to be performed in succession on a given value, they are specified in consecutive instructions. And this is exactly what makes it hard to gain performance through pipelining.
The possible hazards have the following names:
Note that RAW and WAR are two very different things, despite what the World Wrestling Federation might have you believe.
Dealing with these kinds of hazards has influenced the design of pipelined computers.
The IBM STRETCH or 7030 computer was an early attempt at a computer in which the execution phases of instructions were split into parts which could be overlapped. It performed speculative execution of instructions after a branch by always assuming that a branch would not be taken. While reasonable in some cases, as well as simplifying instruction fetch logic, this is precisely the wrong assumption for the conditional branch that ends a loop, often the most common case.
The CDC 6600 was a later computer aimed at achieving a high level of performance with pipelined execution. Instructions to be issued were held in a "scoreboard" until they were ready to be executed. In the case of a WAR hazard, the computer dealt with this by holding the result to be written in the functional unit which calculated it until the read completed; thus, in this case, the available storage provided by the normal set of registers was extended at need, anticipating what follows.
The IBM System/360 model 91 was the pipelined computer for which Tomasulo's algorithm was developed. This algorithm was justly hailed as the right way to make a pipelined computer work efficiently through out-of-order execution.
Pipelined computers are divided into two basic types; simple in-order designs and elaborate out-of-order designs.
As noted on this page, the RISC type of computer architecture has features which reduce the need to accept the costs and complexity of an out-of-order design.
The two basic features of RISC designs which do this are:
So data can be loaded into a register several instructions ahead of the first instruction that does arithmetic on that data, which allows time for that data to be retrieved from external DRAM, which tends to be much slower than on-chip logic.
All three types of data hazards, RAW, WAR, and WAW, can be kept to a minimum, so that the CPU can just deal with them by stalling the instructions involved when they occur, because, with a large number of registers, compilers can make programs more suited to pipelining by interleaving the instructions for unrelated calculations which, therefore, do not have dependencies between one another's instructions.
Currently, however, one will find that many RISC architectures have now been the subjects of out-of-order implementations. The reason for this is because, in the pursuit of higher levels of performance, instruction execution has been split into more parts in order to permit a shorter cycle time, requiring the execution of more instructions to be overlapped. This can exceed the ability of compilers to address by interleaving multiple calculations because of the number of available registers; thus, if one has 32 registers, one might be able to interleave four to eight different calculations, but not much more than that.
The key to the Tomasulo Algorithm is that it makes use of register renaming. When a WAR hazard is encountered, instead of delaying the offending write to ensure that it takes place in correct sequence, after the read instruction that it must not disturb, it is allowed to store its value into a register, but not the same one as the read instruction needs to obtain the previous value from. Instead, an extra register is used as a substitute for the same register, and later instructions that do require the newer value can also proceed immediately, even though an instruction needing the old value is yet to finish, since each value is in its own register from the larger pool.
A WAW hazard can also be addressed by using two different registers for the data to be written. On the other hand, a RAW hazard still requires the instruction needing to read newer data to be delayed until that data is at least available, if not written - an earlier technique, data forwarding, can at least shave off some of the delay by allowing data to be used without necessarily going through a register.
Basically, execution of instructions following the Tomasulo Algorithm proceeds like this:
The instructions initially enter the pipeline unit in sequence.
On the way in, the registers from which instructions read their operands are translated to the actual physical registers in current use as substitutes for those architectural registers.
The registers in which they store their results are checked. If there are pending reads from those registers associated with previous instructions, then a new register is used to store the result, and the translate table is changed for subsequent instructions.
Of course, a stall can still take place if one runs out of physical registers to rename.
Now comes the tricky part of this algorithm. Every instruction that reads from a given register between two writes to that register can notify the pipeline control unit that it has done so; how can the control unit be designed to most simply determine when all the reads are complete? The obvious programming technique of some kind of a stack would clearly be too slow for something that is to be part of a high-performance execution unit.
The first thing that comes to mind is to associate a bit vector with each physical register, and assign each instruction a bit in that vector; thus, one has a stack in effect, but of a short length, and implemented by simple shift logic.
While it's reasonable for the stack to be short in length, since even the most complicated instructions will finish in a limited number of cycles (there are instructions that are exceptions to this, such as those which perform I/O, but they don't need to be handled by this method), it is also entirely possible that a register might be read very many times between writes.
Once the problem is stated, the solution becomes obvious: turn the stack into a circular buffer. When the bit to be assigned an instruction reading a register falls off the end, go around to the beginning, as reads that are old enough are guaranteed to be completed (if this fails, of course, once again a stall can be resorted to; this becomes a sort of structural hazard).
However, this kind of technique is not a part of the Tomasulo algorithm; in fact, the paper in the January 1967 IBM Journal of Research and Development in which he described it specifically rejected such measures as being of a complexity inconsistent with the desired goal of high-speed operation. Could the need for such complexity be avoided since instructions that get operands from registers indicate which registers they are reading directly and plainly in the appropriate fields? While it is true that however many cycles an instruction takes to execute, it can attempt to obtain its operands immediately after being decoded, provided the ISA in question is simple and straightforward in the relevant way, as is that of the System/360, we've just finished seeing how RAW hazards mean that instructions may have to wait before they can fetch their operands.
What technique did Tomasulo use, then?
The secret lies in the Common Data Bus in the 360/91 floating-point unit. Instructions that are waiting for a RAW hazard to be resolved before they can execute are still dispatched to the relevant functional unit after decoding. When an operand value that is being awaited becomes available, it is broadcast to all the functional units along with a tag indicating which register, or substitute register, it came from. The functional units then retain that value for use with future instructions that will also use the same value (thus avoiding unnecessary congestion of the Common Data Bus).
The fact that an instruction can, in the absence of RAW hazards, fetch its inputs immediately after being decoded means that all WAR hazards are the consequence of a WAW hazard; the only thing that delays a read so that it comes after the a write it should precede is the fact that the previous write that the read needed to follow was finished late.
Thus, if one has three writes to the same architectural register, W1, W2, and W3, since W2 is an instruction that follows all the reads requiring the value written by W1, and instructions are capable of reading the data they need from the registers as soon as they've been decoded, it follows that as long as W3 follows W2 by a short, fixed number of cycles, it can re-use the same physical register as was used by W1.
It may be a little trickier than that, as the individual functional units might begin processing the instructions they have buffered at a rate of one per cycle. (It is likely they will not have the capacity to store very many instructions ahead, leading to a structural hazard that will cause unavoidable - but merciful - pipeline stalls as well, thus limiting the degree to which this issue applies.)
Both the CDC 6600 and the IBM 360/91 had one important limitation: imprecise exceptions. Since the execute phase of an instruction was split into small pieces, and several instructions were executing at the same time, if, for example, a divide by zero trap was encountered, there could be instructions preceding the divide instruction involved that had not yet completed.
In the case of the CDC 6600, this was a brand-new computer architecture, so this limitation could just be taken as one of the characteristics of the computer. But the Model 91, on the other hand, was intended to be compatible with other machines in IBM's System/360 line, and that made this a more serious problem for it.
Clearly, though, the problem is fixable. While a program is executing, simply keep a log of the instructions being executed, and take a snapshot of the computer's state after each instruction completes, retaining the most recent snapshot. Then, when a trap takes place, execute the instructions from the most recent snapshot onwards in a non-pipelined manner. (While this could involve shipping them off to an alternate non-pipelined execution unit that uses a limited number of gates, and runs slowly, another option is to complete them one at a time, from their current state of partial completion, in the main pipelined execution unit where they are.)
Of course, a snapshot of the state of a computer could contain a lot of data, so some further clarification is in order. We will only worry about register contents and internal things like condition flags: data to be written to memory must not make it even as far as the cache until the instruction is considered completed. (Of course, when writing data to memory is one of the things an instruction is supposed to do, the instruction isn't really complete until that has been done: for pipeline purposes, though, a different definition of "complete", one, admittedly, with which you may not be familiar, must be used. (It isn't plagiarism if people get the Hitchhiker's Guide reference!)) Furthermore, it isn't necessary to copy the register contents anywhere; one just associates a flag with a register (including, remember, these pesky renamed registers) to indicate that it has been written to by an instruction not yet completed (keeping track of stuff so that these flags can get cleared is... clearly... doable).
While this is reasonable and obvious enough, questions remain. In the case of a trap such as a divide by zero, it may not be the case that the programmer is seeking a core dump and an expression of the machine's state at the time of the failure in conventional terms; so being able to set a flag to turn off making an effort to have precise exceptions might be desirable.
In other cases, though, an exception is normal, and the machine state does need to be saved so that execution can resume. Thus, an instruction that reads data from memory may experience not just a cache miss - but the data might actually be in the swap file on disk, if virtual memory is in use.
Here, execution needs to resume without skipping a beat, and the pipeline can't hold the instructions in flight while waiting for the data, since there are other threads to execute.
But that doesn't mean it's necessary to have a precise exception - instead, the machine state could be saved in an internal format, including all the partly-finished instructions with an exact description of just how partly-finished they are.