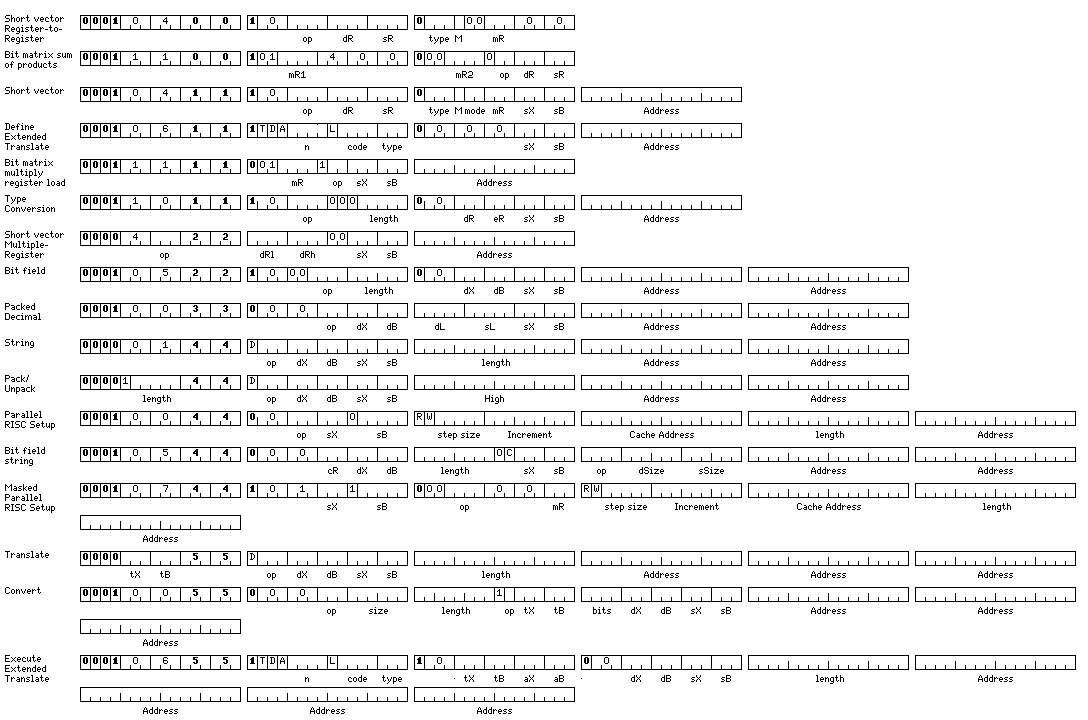
One major group of the additional instructions, the character and packed decimal instructions and those related to them is discussed here. These instructions are normally memory-to-memory two-address instructions, and thus a diagram showing the instruction formats for most of the longer instructions, including some not discussed in this section, is shown below:
These instructions are available from Normal Mode and Compressed Mode.
In Simple Mode, the following rule applies:
Normal Mode Simple Mode Compact Mode ---------------- ---------------- 0000abcdefxyzxyz 1abcdefxyzxyz000 00010bcdefxyzxyz 01bcdefxyzxyz000 00011bcdefxyzxyz (not available)
These are the opcodes of the instructions from that illustration with which we will concern ourselves here:
Normal Simple Compact -------------------- -------------------- 010611 1xxxxx 0000xx 046110 1xxxxx 0000xx DET Define Extended Translate 011011 1000xx 00xxxx 050110 1000xx 00xxxx CVPB Convert Packed to Byte 011011 1004xx 00xxxx 050110 1004xx 00xxxx CVBP Convert Byte to Packed 011011 1010xx 00xxxx 050110 1010xx 00xxxx CVPH Convert Packed to Halfword 011011 1014xx 00xxxx 050110 1014xx 00xxxx CVHP Convert Halfword to Packed 011011 1020xx 00xxxx 050110 1020xx 00xxxx CVPW Convert Packed to Word 011011 1024xx 00xxxx 050110 1024xx 00xxxx CVWP Convert Word to Packed 011011 1030xx 00xxxx 050110 1030xx 00xxxx CVPL Convert Packed to Long 011011 1034xx 00xxxx 050110 1034xx 00xxxx CVLP Convert Long to Packed 011011 1040xx 00xxxx 050110 1040xx 00xxxx CVPM Convert Packed to Medium 011011 1044xx 00xxxx 050110 1044xx 00xxxx CVMP Convert Medium to Packed 011011 1050xx 00xxxx 050110 1050xx 00xxxx CVPF Convert Packed to Floating 011011 1054xx 00xxxx 050110 1054xx 00xxxx CVFP Convert Floating to Packed 011011 1060xx 00xxxx 050110 1060xx 00xxxx CVPD Convert Packed to Double 011011 1064xx 00xxxx 050110 1064xx 00xxxx CVDP Convert Double to Packed 011011 1070xx 00xxxx 050110 1070xx 00xxxx CVPQ Convert Packed to Quad 011011 1074xx 00xxxx 050110 1074xx 00xxxx CVQP Convert Quad to Packed 010033 0000xx 040330 0000xx MESTP Multiply Extensibly and Store Packed 010033 0001xx 040330 0001xx CP Compare Packed 010033 0002xx 040330 0002xx MVP Move Packed 010033 0003xx 040330 0003xx DSTRP Divide and Store Remainder Packed 010033 0004xx 040330 0004xx AP Add Packed 010033 0005xx 040330 0005xx SP Subtract Packed 010033 0006xx 040330 0006xx MP Multiply Packed 010033 0007xx 040330 0007xx DP Divide Packed 000144 01xxxx 101440 01xxxx CC Compare Character 000144 11xxxx 101440 11xxxx CCH Compare Halfword Characters 000144 02xxxx 101440 02xxxx MVC Move Character 000144 12xxxx 101440 12xxxx MVCH Move Halfword Characters 004x44 02xxxx 14x440 02xxxx P Pack 004x44 12xxxx 14x440 12xxxx PH Pack Halfword 004x44 03xxxx 14x440 03xxxx U Unpack 004x44 13xxxx 14x440 13xxxx UH Unpack Halfword 010055 0000xx xxx2xx 040550 0000xx xxx2xx CV Convert 010055 0001xx xxx2xx 040550 0001xx xxx2xx CVR Convert Reversed 010055 0003xx xxx2xx 040550 0003xx xxx2xx CVRI Convert Reversed Incomplete 010055 0004xx xxx2xx 040550 0004xx xxx2xx CVBF Convert Bit Field 010055 0000xx xxx3xx 040550 0000xx xxx3xx DCV Displaced Convert 010055 0001xx xxx3xx 040550 0001xx xxx3xx DCVR Displaced Convert Reversed 010055 0003xx xxx3xx 040550 0003xx xxx3xx DCVRI Displaced Convert Reversed Incomplete 010055 0004xx xxx3xx 040550 0004xx xxx3xx DCVBF Displaced Convert Bit Field 00xx55 00xxxx 1xx550 00xxxx TBH Translate Byte to Halfword 00xx55 01xxxx 1xx550 01xxxx TTHB Table Translate Halfword to Byte 00xx55 02xxxx 1xx550 02xxxx T Translate 00xx55 12xxxx 1xx550 12xxxx TH Translate Halfword 00xx55 04xxxx 1xx550 04xxxx FMT Format 00xx55 14xxxx 1xx550 14xxxx FMTH Format Halfword 00xx55 05xxxx 1xx550 05xxxx SC Scan 00xx55 15xxxx 1xx550 15xxxx SCH Scan Halfword 010655 1xxxxx 10xxxx 046550 1xxxxx 10xxxx EET Execute Extended Translate
and these instructions, with the exception of the define and execute extended translate instructions, are discussed below.
For the P and U instructions, the value of the length field is one less than the length in digits of the shorter of the two operands. The length in bytes of the longer of the two operands is as many bytes as the shorter operand has digits; in the case of the PH and UH instructions, the length of the longer operand is that number of halfwords.
When the number of digits is an odd number, the number of bytes occupied in memory by the operand will be half of one more than the number of digits, with an extra digit position preceding the most significant digit ignored when a value is obtained for an instruction, and cleared when a result is stored. As will be seen below, the decimal format used precludes sign extension in this case.
As will be described later, a mode is available in which data memory is treated as being organized in units other than 32-bit words. In that case, the constraint on the number of digits of a packed decimal operand is different in some cases.
24 bit word 6 bit character: divisible by 3 8 bit character: divisible by 2 30 bit word 6 bit character: divisible by 3 10 bit character: divisible by 5 32 bit word 8 bit character: divisible by 2 36 bit word 9 bit character: divisible by 9 6 bit character: divisible by 3 40 bit word 10 bit character: divisible by 5 8 bit character: divisible by 2
When the bit in the Program Status Block indicating compressed decimal operation is set, length fields referring to packed decimal operands indicate their length in characters instead of in digits; the reasons for this are dealt with on this page; in the case of a 30 or 40 bit word, and a 10 bit character, a restriction to numbers of digits divisible by 3 could be applied, but in other cases, the situation is much more complicated.
Also, note that the length field contains the actual length of the operand in characters, while when the length field indicates the length of an operand in digits, it contains one less than the length of the operand in digits.
The P instruction copies the least significant four bits of each byte of the source operand into consecutive four-bit areas of the destination operand; the U operand copies four-bit areas of the source operand into the least significant four bits of each byte of the destination operand, filling the most significant bits of those bytes with the contents of the High field of the instruction.
Some typical values of that field would be:
0000000000000010 ASCII 0000000000000011 BCDIC 0000000000001111 EBCDIC
When the computer is in the mode in which the width of memory containing data has been modified, which, as noted above, will be explained in a later section, if the character size is larger than eight bits, (it may be either nine or ten bits in some cases) some of the bits other than the last four may be used even when the D bit is zero.
When the D bit is one, then this instruction converts between four-bit packed decimal digits and sixteen-bit characters, such as may be used with UNICODE. In that case, normally the last twelve bits, rather than the last four bits, of the high field would be used. With an enlarged character size, double-width characters can be eighteen or twenty bits in width, which is why a sixteen-bit high field is required in the instruction.
With a 30-bit word, a 15-bit character size is also possible, but in that case, the most significant ten bits of characters will simply be filled with zeroes, since a double-width character in that case would not normally be used as a character.
Note that these instructions convert to and from conventional string representations of numbers. In the case of a negative number, as represented in ten's complement format, the number is treated as unsigned; thus, the value -1 will be converted to a string of digits consisting entirely of the digit 9. It does not convert to or from the true zoned decimal format, in which the units digit contains zone bits indicating the sign of the number.
In order to simplify computing with packed decimal quantities as much as possible, these quantities are currently envisaged as being stored in a modified ten's complement format.
The following table shows how the first digit of a packed decimal quanity is to be expanded to create a ten's complement number one digit larger than the number of digits in its representation:
0: 00 1: 01 2: 02 3: 03 4: 04 5: 05 6: 06 7: 07 8: 08 9: 09 A: 94 B: 95 C: 96 D: 97 E: 98 F: 99
thus, a four-digit packed decimal quanity may range in value from -6000 (94000) to 9999 (09999), as shown below:
Internal Five-digit Value form ten's complement 9999 09999 9999 9998 09998 9998 9997 09997 9997 ... 0002 00002 2 0001 00001 1 0000 00000 0 F999 99999 -1 F998 99998 -2 ... A002 94002 -5998 A001 94001 -5999 A000 94000 -6000
Prior to printing, a negative value may be converted to positive by subtraction. Since negative values usually need special processing in order to print the minus sign, this does not seem unreasonable.
Because decimal arithmetic is intended to provide a means of performing a few arithmetical operations quickly on data retrieved from storage in printable form, and then returned there after only a limited number of calculations, maintaining a close relationship between the internal representation of decimal numbers and their printed form takes priority over the speed of decimal arithmetic. Thus, while the use of a ten's complement representation for negative numbers was envisaged above, normally the appropriate internal representation of signed decimal numbers would appear to be a sign-magnitude representation.
For numbers in sign-magnitude form, using the six values for the first digit not used in normal BCD to indicate a negative sign in a fashion similar to that used above would still be possible:
0: +0 1: +1 2: +2 3: +3 4: +4 5: +5 6: +6 7: +7 8: +8 9: +9 A: -0 B: -1 C: -2 D: -3 E: -4 F: -5
Given, however, that a packed decimal number is stored as a certain number of bytes, and therefore must be at least two digits long, and a byte can have 256 possible values, which is more than 200, the question arises as to whether there might be a simple way to allow negative numbers to also begin with any digit up to 9 without the overhead of a full BCD digit for the sign.
This certainly is possible. The sign could be stored in the first bit of the first byte, followed by seven bits representing the first two digits of the number, either in binary form, or in seven-bit Chen-Ho encoding.
However, an even simpler method is possible:
+0n 0n -0n An +1n 1n -1n Bn +2n 2n -2n Cn +3n 3n -3n Dn +4n 4n -4n En +5n 5n -5n nA +6n 6n -6n nB +7n 7n -7n nC +8n 8n -8n nD +9n 9n -9n nE
To allow ten possible values for the first digit of a negative number, use five unused codes in the first place for five of them, and for the other five, use the five unused codes in the second place, where they indicate a larger value for the first digit, and that the codings for the first two digits are swapped within the first byte.
This scheme might be called Zero Overhead Negative Number Coding, or ZONNC.
A perhaps improved modification of this scheme would be:
+0n 0n -0n 8n +1n 1n -1n 9n +2n 2n -2n An +3n 3n -3n Bn +4n 4n -4n Cn +5n 5n -5n Dn +6n 6n -6n En +7n 7n -7n Fn +8n nC -8n nE +9n nD -9n nF
allowing simpler determination of the sign, with one of two bits acting as a sign bit depending on a simple condition.
The divide and store remainder packed instruction, in addition to replacing the destination operand by the quotient of the division, also replaces the source operand by the remainder. This ensures that each result is placed in a field of adequate width, and it avoids the need to inspect the result to separate the quotient from the remainder, as would be required if the form of the divide packed instruction in some other architectures was followed. The divide packed instruction only produces a quotient in the destination field, just as do the binary fixed-point and floating-point divide instructions.
The Multiply Extensibly and Store Packed instruction places the leftmost part of the product in the source operand, with the rightmost part of the product being placed in the destination operand, to allow products of numbers both more nearly filling their fields to be calculated.
It should be noted that, because on the one hand, decimal arithmetic is intended to be implemented using parallel ALUs, not digit-serial ALUs, and on the other hand, it is intended for uses in which it is closely tied to the character representation of numbers, there are certain somewhat involved considerations that apply if little-endian operation is selected. In that mode, normally packed decimal quantities are little-endian as well, but they are then addressed by the byte at the highest address, unlike operands of every other type, so that the address points to the most significant digit of a packed decimal number just as normal addresses point to the most significant digit of a character string containing a number in printed form.
An additional bit in the program status quadword can reverse this situation, by reversing the order in which digits are stored in numbers converted to character format. This permits consistent operation with languages having a right-to-left direction of writing, where a simple character code of glyphs is used, rather than one like UNICODE, in which different characters can have different directions of writing associated with them. Complete details on this are given in a later section.
The format of the type conversion instructions is somewhat similar to that of the packed decimal instructions. As only one operand is of the packed decimal type, the dL field is used to indicate the direction of conversion, and the type of the other operand.
For integer conversions, the dX field serves instead as a dR field, indicating the register used as the other operand.
For floating-point conversions, the dX field indicates the register containing the floating-point number on one side of the conversion, and the dB field indicates the fixed-point register, always used to contain a 32-bit quantity, which is on the same side of the conversion as the packed decimal operand, and which is used to contain the exponent, as a power of 10, by which the number expressed by the packed decimal operand is to be multiplied. The packed decimal operand is considered to have an implied decimal point immediately prior to its second digit for the purpose of this instruction (all other packed decimal arithmetic operations treat packed decimal quantities as integers, with an implied decimal point after the last digit), and the first digit will be used only to indicate the sign of the number being converted.
The first operand of the T instruction is a block of exactly 256 bytes which is used as a translation table. Bytes taken from the source operand are used as indexes into this table, and the entries found therein are copied to the destination operand in corresponding positions.
The first operand of the TH instruction is a block of exactly 65,536 halfwords which is used as a translation table. Halfwords taken from the source operand are used as indexes into this table, and the entries found in it are copied to the destination operand one after another.
The first operand of the TBH instruction is a block of exactly 256 halfwords, which is used as a translation table. The bytes in the source operand are used as an index into the table, and the result stored in the destination operand is built up from the halfwords indexed in that table.
The first operand of the TTHB instruction is a series of blocks of 256 bytes, of which the first contains numbers from 0 up to, possibly, 255, which are indexes to other tables. These other tables are the following blocks of 256 bytes; the second block being table 0, the third table 1, and so on.
Halfwords are taken from the source operand. The first byte of each halfword is taken as an index to the first table, which then indicates which of the other tables is to be used, in conjunction with the second byte of the halfwords as the index into that other table, to produce the byte to be stored in the destination operand corresponding to the halfword from the source operand.
This instruction is useful in converting text in UNICODE to an 8-bit character code for a particular language.
The FMT instruction operates as follows: The first operand is a translation table with 256 one-byte entries in which entries 0, 1, and 255 have a special significance. (The significance of 255 will, of course, be posessed instead by 65,535 in the FMTH instruction, and if the character length in bits is altered, this significance will be held by the maximum possible value in each case.) The length field of the instruction determines the length of the source operand. Successive characters from the source operand are moved to the destination operand as follows:
This instruction, except that it does not convert from packed decimal to unpacked, performs a similar function to the edit and edit with mark instructions on the IBM System/360 computer. Thus, a translation table can contain a fill character in position 0, the digit zero in position 1, and a floating currency symbol (or another fill character) in position 255 to convert a raw zoned decimal string (produced by an unpack instruction) to the format used in printing. Note that the decimal point would be placed in the destination operand, with zero bytes in the positions to be filled with digits.
The SC instruction begins by ignoring any characters in the source operand that translate to bytes containing zero in the translation table; then, bytes not translating to zero are copied with translation until an entry in the translate table containing a zero is encountered. The number of characters translated is placed in accumulator/index register 2, giving the length of the result in the destination operand, and the number of characters translating to zero that were initially ignored, plus the number of characters translated, is placed in accumulator/index register 1, giving the portion of the source operand that was scanned until the first character translating to zero following a character not translating to zero was found, and the remainder of the destination operand is filled with the character found in position 0 of the translate table.
The source operand may not contain a byte having the value 0. If it does, the instruction stops, and an overflow condition is set.
If the instruction completes within the provided length, then it is treated as having a zero result for a subsequent conditional branch instruction; if it did not complete, but characters with nonzero translations were encountered, it has a positive result; if only characters translating to zero were encountered, it has a negative result.
This instruction can be used for some of the same purposes as the translate and test instruction of the IBM System/360, although it works differently. It can be used to scan for keywords and translate them to upper case, for example.
It might be argued that instructions such as FMT and SC, as well as other specialized instructions of this architecture, are not useful because a compiler would not normally make use of them. While it is true that a compiler, seeing an algorithm for converting a number to decimal form for printing expressed in terms of assignment statements and IF statements, is unlikely to deduce that it can use specialized conversion and editing instructions to accomplish the task more quickly, it is also expected that most of the time, conversion from binary to decimal will take place in formatted output statements, and the routines which they use will have been written directly in assembly language, to make use of the relevant instructions.
Of course, that assumes the run-time library of the compiler was written especially for the given architecture, to obtain the best possible performance, rather than simply compiled from portable C code, which may well initially be the case for new machines and certain operating systems.
The Convert instruction, CV, is modelled on the Convert instruction of the IBM 7094 computer and its predecessors.
This instruction has three operands, a source, a destination, and a translation table.
Unlike a translate instruction, which applies a single table of substitutes to each character of the string on which it operates, this instruction can change which table of substitutes it uses from one character to the next, and so the translation table operand for this instruction is not a simple table of substitutes. Instead, the translation table contains a number of tables of substitutes, and each table of substitutes, instead of being composed of 8-bit entries containing only a substitute, is composed of 32-bit entries, consisting of, first, an 8-bit substitute, and then a 24-bit pointer to the next table of substitutes to use.
The details of the operation of this instruction will be explained below.
The Convert instruction on the IBM 7094 performed this type of translation once, on the successive characters contained in a register. This instruction, instead, operates on a series of strings in memory, beginning with the first table of substitutes on the first character of each of those strings.
The source and destination operands of the instruction are considered to consist of a number of strings indicated in the length field, each string having a size in bytes indicated in the size field.
Each of the strings is processed as follows:
The first byte is treated as an index into a table of 256 32-bit words, which is the table operand to the instruction. The first byte of the word indexed is taken as the translated version of the character, and is placed in the corresponding position of the destination operand. The remaining 24 bits of the word are taken as a signed displacement in units of 32-bit words, which, relative to the effective address of the table operand of the instruction, points to the table used for processing the next byte in the string.
This operation is repeated until the end of the string.
Making the displacement signed is useful for allowing the Convert Reversed instruction to serve as a decimal adjust instruction with tables of minimum length. Note, therefore, that the tables can overlap.
The Convert Reversed instruction begins processing each string with its last character, and works backwards towards the first character of the string.
The Convert Reversed Incomplete instruction handles the size field of the instruction in a special manner. The first two bits of that field indicates the size of the strings handled by the instruction as follows:
00: two bytes 01: four bytes 10: eight bytes 11: sixteen bytes
and the remaining four bits of the field indicate the number of bytes at the beginning of each string that are to be ignored by the instruction instead of processed.
In the preceding instructions, the bits field of the instruction is not used and must be zero.
In the Convert Bit Field instruction, the bits field indicates the length in bits of the elements in a string that are to be converted; if it is zero, it indicates that 16-bit elements are to be used. The addresses in this instruction are bit displacements instead of byte displacements, as they are for the additional bit field instructions in Extended Operate mode.
In the Displaced convert instructions, the latter three bytes of a table entry are taken as relative to the value in the base register used in the instruction instead of the effective address of the translate table. In this way, a single table in memory can be used with different portions of that table serving as the first translate table used, without the choice of a different starting point having the effect of changing the interpretation of pointers to substitution tables within the translate table.
Note that tables used with the displaced convert instructions and the regular convert instructions are compatible; if one starts with the main part of a table, one does not need to set up a base register to point directly to that part, but if one needs to start elsewhere, only then is that overhead incurred, and then the displaced instructions need to be used.
The DET and EET instructions do not have the same format as the translate instructions, although they have a related function, thus, although their instructions belong to the translate group, they will be dealt with in a later section.