This section describes several additional features available in this mode over and above basic memory-reference operations applied to vectors.
It describes extra instructions that perform functions such as setting mask bits based on the individual elements of a vector, other extra instructions that assist with performing the Fast Fourier Transform, and a class of instructions that allows different operations to be performed in parallel on the individual elements of a vector.
Instructions for setting mask bits corresponding to the values in a vector were present among the short vector instructions. These instructions were special instructions, not standard memory-reference instructions, but had four-bit opcodes patterned after those of the standard memory-reference instructions, along with a separate three-bit byte indication, as part of the second word of the instruction.
Instructions having this function are also provided for use with those long vector addressing modes that have a long vector register as their destination. These instructions, however, are standard memory-reference instructions.
No opcodes exist corresponding to the opcodes used for this purpose with short vectors for the floating types, however. As this is a function requiring only one operand, this is dealt with by performing the integer operation when the destination register is zero, and the corresponding floating-point operation when the destination register is four.
The opcodes so used are the ones corresponding to the unsigned compare, multiply extensibly, and divide extensibly instructions, which are not usable with long vectors.
The same opcodes apply to these instructions as to those pictured above. However, the unsigned compare, multiply extensibly, and divide extensibly operations are not applicable for long vector operations, and thus their opcodes are instead used for instructions used to set up mask registers. Since these are integer operations, and they are single-operand instructions, the floating-point versions of the operations are indicated by a destination register value of four:
Normal Simple Compact ------------- ------------- 002x11 001110 12x110 001110 SMBLVZB Set Mask Bit Long Vector if Zero Byte 002x11 001610 12x110 001610 SMBLVPB Set Mask Bit Long Vector if Positive Byte 002x11 001710 12x110 001710 SMBLVNB Set Mask Bit Long Vector if Negative Byte 002x11 001114 12x110 001114 SMBLVZM Set Mask Bit Long Vector if Zero Medium 002x11 001614 12x110 001614 SMBLVPM Set Mask Bit Long Vector if Positive Medium 002x11 001714 12x110 001714 SMBLVPM Set Mask Bit Long Vector if Negative Medium 002x11 003110 12x110 003110 SMBLVZH Set Mask Bit Long Vector if Zero Halfword 002x11 003610 12x110 003610 SMBLVPH Set Mask Bit Long Vector if Positive Halfword 002x11 003710 12x110 003710 SMBLVNH Set Mask Bit Long Vector if Negative Halfword 002x11 003114 12x110 003114 SMBLVZF Set Mask Bit Long Vector if Zero Floating 002x11 003614 12x110 003614 SMBLVPF Set Mask Bit Long Vector if Positive Floating 002x11 003714 12x110 003714 SMBLVPF Set Mask Bit Long Vector if Negative Floating 002x11 005110 12x110 005110 SMBLVZ Set Mask Bit Long Vector if Zero 002x11 005610 12x110 005610 SMBLVP Set Mask Bit Long Vector if Positive 002x11 005710 12x110 005710 SMBLVN Set Mask Bit Long Vector if Negative 002x11 005114 12x110 005114 SMBLVZD Set Mask Bit Long Vector if Zero Double 002x11 005614 12x110 005614 SMBLVPD Set Mask Bit Long Vector if Positive Double 002x11 005714 12x110 005714 SMBLVND Set Mask Bit Long Vector if Negative Double 002x11 007110 12x110 007110 SMBLVZL Set Mask Bit Long Vector if Zero Long 002x11 007610 12x110 007610 SMBLVPL Set Mask Bit Long Vector if Positive Long 002x11 007710 12x110 007710 SMBLVNL Set Mask Bit Long Vector if Negative Long 002x11 007114 12x110 007114 SMBLVZQ Set Mask Bit Long Vector if Zero Quad 002x11 007614 12x110 007614 SMBLVPQ Set Mask Bit Long Vector if Medium Quad 002x11 007714 12x110 007714 SMBLVPQ Set Mask Bit Long Vector if Negative Quad
These opcodes, that is, the ones for the unsigned compare, multiply extensibly, and divide extensibly instructions, can also be used for setting mask bits based on the contents of a vector register, or a vector scratchpad element, by using them within the vector register address format, or the vector scratchpad to vector register address format, respectively.
With long vectors, the medium and quad types are allowed, unlike the case of short vectors. This is true both of the long vector registers and the register scratchpad. And the mask bits are only used to control operations involving those registers as well.
In the memory to memory vector instructions of constant and reversed constant type, the S bit, which replaces the I bit for the constant register operand, indicates if 0 that it is found in one of the regular registers, and is indicated by the oR or sR field, and if 1 that it is found in one of the supplementary registers, and is indicated by the oS or sS field of the instruction.
As the identities of the low and high scratchpad registers define the length, the vector-to-scratchpad instructions need no length field; they are similar to multiple-register instructions. None of the vector instruction formats allows the multiply extensibly or divide extensibly instructions, as they have operands of unequal length.
In the vector register constant and vector scratchpad constant modes, the R bit in the instruction allows the destination vector to be subtracted from the source scalar, or the source scalar to be divided by the destination vector, in forming the result to be placed in the destination vector.
The seven-bit opcode 0110000, which would correspond to an "insert long" instruction, is used for those addressing modes in which the destination is the supplementary registers, for the LTL (Load Transposed Long) instruction. This instruction loads the 64 supplementary arithmetic-index registers with the bit matrix transpose of the operand consisting of 64 values each 64 bits long. Using this instruction twice, combined with rearranging the individual 64-bit values in the supplementary arithmetic/index registers, and moving them out, allows sixty-four bit transpositions on 64-bit words to be carried out in parallel.
As with vector mode, the opcodes that would be used for compare instructions instead specify multiply and accumulate instructions when used in conjunction with long vector instruction formats, giving the following opcodes for these operations:
Normal Simple Compact ------------- ------------- 002x11 002110 12x110 002110 MAH Multiply and Accumulate Halfword 002x11 004110 12x110 004110 MA Multiply and Accumulate 002x11 006110 12x110 006110 MAL Multiply and Accumulate Long 002x11 010110 12x110 010110 MAM Multiply and Accumulate Medium 002x11 012110 12x110 012110 MAF Multiply and Accumulate Floating 002x11 014110 12x110 014110 MAD Multiply and Accumulate Double 002x11 016110 12x110 016110 MAQ Multiply and Accumulate Quad
And one of the additional bits provided with a ten-bit opcode field is used to specify the Bit Reversed Load and Shuffle operations which are used to assist with Fourier transforms:
002x11 4001xx BRL16B 002x11 4201xx BRL16H 002x11 4401xx BRL16 002x11 4601xx BRL16L 002x11 4021xx BRL32B 002x11 4221xx BRL32H 002x11 4421xx BRL32 002x11 4621xx BRL32L 002x11 4031xx SH32B 002x11 4231xx SH32H 002x11 4431xx SH32 002x11 4631xx SH32L 002x11 4041xx BRL64B 002x11 4241xx BRL64H 002x11 4441xx BRL64 002x11 4641xx BRL64L 002x11 4051xx SH64B 002x11 4251xx SH64H 002x11 4451xx SH64 002x11 4651xx SH64L 002x11 4061xx US128B 002x11 4261xx US128H 002x11 4461xx US128 002x11 4661xx US128L 002x11 4071xx SH128B 002x11 4271xx SH128H 002x11 4471xx SH128 002x11 4671xx SH128L 002x11 5001xx BRL16M 002x11 5201xx BRL16F 002x11 5401xx BRL16D 002x11 5501xx BRL16Q 002x11 5021xx BRL32M 002x11 5221xx BRL32F 002x11 5421xx BRL32D 002x11 5521xx BRL32Q 002x11 5031xx SH32M 002x11 5231xx SH32M 002x11 5431xx SH32D 002x11 5531xx SH32Q 002x11 5041xx BRL64M 002x11 5241xx BRL64F 002x11 5441xx BRL64D 002x11 5541xx BRL64Q 002x11 5051xx SH64M 002x11 5251xx SH64F 002x11 5451xx SH64D 002x11 5551xx SH64Q 002x11 5061xx US128M 002x11 5261xx US128F 002x11 5461xx US128D 002x11 5561xx US128Q 002x11 5071xx SH128M 002x11 5271xx SH128F 002x11 5471xx SH128D 002x11 5571xx SH128Q
These are the various Bit-Reversed Load instructions and the various Shuffle instructions.
Again, in Simple Mode, the first halfword of these instructions, 002x11, becomes 12x110, following the general rule given above.
For the BRL64 instructions, the range must be the range of locations within a vector:
(0,63)
and the instruction loads register abcdef (in binary) of the destination from register fedcba of the source. This operation has some use with the Fast Fourier Transform algorithm, as we will see below.
For the BRL32 instructions, the range must be one or both of the ranges:
(0,31)(32,63)
and within each range, register xabcde of the destination is loaded from register xedcba of the source.
For the BRL16 instructions, the range must be any contiguous combination of the following subranges:
(0,15)(16,31)(32,47)(48,63)
and within each range, register xxabcd of the destination is loaded from register xxdcba of the source.
Thus, a BRL16 instruction takes elements 0 through 16 of the source, and places them in the destination in the order:
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
The SH32 and SH64 instructions have the same ranges as the BRL32 and BRL64 instructions. A Shuffle instruction combines elements from the first and second halves of each subrange in the source by taking one element from each half in turn alternately.
Thus, an SH32 instruction takes the elements 0 through 31 of the source, and places them in the destination in the order:
0 16 1 17 2 18 3 19 4 20 5 21 6 22 7 23 8 24 9 25 10 26 11 27 12 28 13 29 14 30 15 31
The range given for an SH128 instruction must also be from 0 to 63, but its operands must be even-numbered long vector registers or long vector scratchpad locations, as the source and destination are considered to be the entire addressed register and the entire register following.
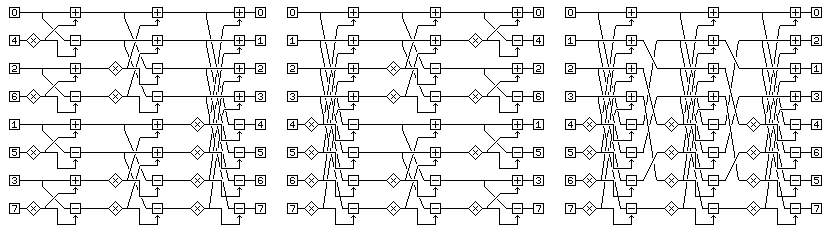
The shuffle instructions are also intended for use in performing Fast Fourier Transform calculations. One long vector register would normally contain the real parts of the numbers involved, and another one the complex parts: the diagram below, showing the classic Cooley-Tukey Fast Fourier Transform algorithm in its original form, followed by the reversed, or Sande-Tukey form of the algorithm, shows why the shuffle operation is highly useful to an efficient fast Fourier transform using vector arithmetic.
All three formulations are equivalent, but the third performs all its operations with vectors of the maximum length. Since the operations, in this eight point FFT, use vectors of four items, it is also clear why, given the ability to perform vector operations on vectors with 64 elements, the SH128 instruction needed to be defined.
Note that while the operation in the last column of the FFT using a shuffle after each stage appears the same as that for the classic Cooley-Tukey algorithm, the elements of the transformed vector are not in natural order, but are in bit-reversed order within each half, which makes bit-reversed operations having half the length of the shuffle used still relevant. Thus, the algorithm illustrated in the third part of the diagram is the Pease framework for the Fast Fourier Transform.
It is intended that a 128-point FFT would make use of the SH128 and BRL64 instructions, where the real parts of the first 64 points, the imaginary parts of the first 64 points, the real parts of the second 64 points, and the imaginary parts of the second 64 points would each occupy a vector.
The US128 instructions perform the inverse operation of the SH128 instructions, and are used in converting arrays of complex numbers into separate vectors of their real and imaginary parts.
It should be noted that a more modern form of the Fast Fourier Transform, the Stockham framework, is currently more popular than the Pease framework:
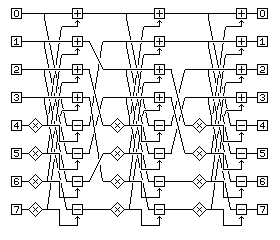
This form of the FFT corrects the flaw of the Pease framework, and presents its result with elements in order. However, a different transposition of vector elements is required at each stage of the algorithm, first a shuffle of individual elements, then a shuffle of pairs of elements, then a shuffle of groups of four elements, and so on. For hardware acceleration with 64-element vectors, therefore, the Stockham framework requires that five special operations be defined, while the Pease framework requires only two: SH128 and LBR64. In the case of short vector operations, where the length of the vector, rather than the number of its elements, is fixed, it is the Stockham framework rather than the Pease framework which is simpler to implement, and thus it is the framework for which hardware assist instructions are provided there.
When the op2 field equals 2, another set of useful operations involving rearranging the items within a vector of 64 elements is provided.
Once again, the first four bits of the main opcode indicate the type of the operands:
0000 byte 0010 halfword 0100 integer 0110 long 1000 medium 1001 floating 1010 double 1011 quad
and this time the last three bits indicate displacements:
X Y
000 -1 -1
001 0 -1
010 +1 -1
011 -1 0
100 +1 0
101 -1 +1
110 0 +1
111 +1 +1
where the 64 elements of a long vector are considered to be arranged in a square array in the following order:
56 57 58 59 60 61 62 63 48 49 50 51 52 53 54 55 40 41 42 43 44 45 46 47 32 33 34 35 36 37 38 39 24 25 26 27 28 29 30 31 16 17 18 19 20 21 22 23 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7
and a displacement of (+1,0) means that element 18 is loaded from element 19, increased by one in the X direction; a displacement of (0,+1) means that element 18 is loaded from element 26, an increase of one in the Y direction.
The instruction is maskable, and the rows and columns are both considered to wrap around, so that if 7 comes after 6, 0 comes after 7. These instructions allow values in a long vector to interact with their nearest neighbors where a long vector is considered to be acting as part of a two-dimensional array of numbers.
In order to keep the 64 arithmetic-logic units of the long vector unit as busy as possible, while stopping short of having 64 separate instruction streams, instruction modes are defined in which one to three mask registers can be designated in an instruction.
This type of operation is available under the same terms as the three-address long vector instructions: from Normal Mode, Scratchpad Mode, Condensed Mode, Compact Mode and Local Mode and with modified opcodes from Simple Mode as well, since it is indicated by a prefix consisting of a register-to-register instruction invalidated by having the same register as source and destination.
If one mask register is designated, instead of merely indicating whether or not an operation is performed, it indicates which of two operations are performed.
Similarly, two mask registers indicate, by means of their corresponding bits, which of four operations are performed on each of the 64 values accessed in parallel in the supplementary registers, the long vector registers, or the long vector scratchpad.
And three mask registers indicate one of eight possible operations.
The type field in the instruction has the usual interpretation, and can indicate fixed-point as well as floating types.
The possible operations are:
000 no operation 001 subtract reversed 010 load 011 divide reversed 100 add 101 subtract 110 multiply 111 divide
There is a load instruction, causing the destination to be replaced by the source, but no store instruction, since that cannot easily be executed in parallel with the other operations.
Subtract reversed replaces the destination with the source minus the destination, and divide reversed replaces the destination with the source divided by the destination.
The bottom portion of the diagram shows the last part of the instruction, having the same form for two-way, four-way, and eight-way instructions, which gives the two operands to the instruction.
The instructions used for this feature have the following form:
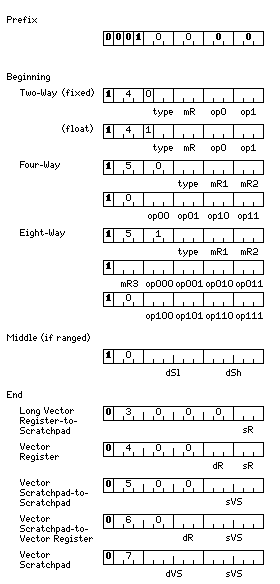
The possible operations specified by each of the three-bit operation fields are:
000 no operation 001 subtract reversed 010 load 011 divide reversed 100 add 101 subtract 110 multiply 111 divide
Each instruction begins with the 16-bit prefix for operate instructions, and then includes a beginning part, in the format shown.
The prefix becomes 100000 instead of 010000 in Simple Mode.
The two-way vector operation instructions, if acting on fixed-point vectors, occupy the opcode space left over from standard register to register instructions; if acting on floating-point vectors,they occupy the opcode space continuing from standard memory-reference instructions. In both case, the opcode space left over by the fact that a standard seven-bit opcode does not begin with the first two bits equal to 11 is used.
The opcode space left over by the load and store instructions with standard indexing when the base register is zero, as this is not needed to indicate an alternate way of expressing register to register forms of these instructions is what is used by both the four-way and eight-way vector operation instructions.
Each instruction also includes an end part, in the format shown in the diagram. Note that the end part of the instruction always begins with a 1.
When a halfword beginning with a 0 is found immediately after the end of the beginning part of the instruction, that means this halfword is the middle part of the instruction, and that the instruction is ranged; the low and high destination scratchpad fields of the instruction specify the start and end of the contiguous group of elements, from among the possible 64 elements of a vector, that are operated upon by the instruction.