
This section looks at cipher machines that worked with teletypewriters.
Just as today's computers represent printed characters as 8-bit bytes using the ASCII code, teletypewriters used a similar code for communications purposes. However, they used only five bits per character, which conserved bandwidth, although it meant that shifting between letters and other characters such as numbers and punctuation marks required sending characters that indicated a shift was taking place.
Thus, we have a family of cipher machines that, before the computer age, was already working in binary code.
Two early American attempts at a telecipher machine were not used in practice, since they were found to be insecure. One was designed by Gilbert S. Vernam for A. T. & T., the two-tape machine, where two punched tape loops of unequal size each provided a current character to be XORed with the plaintext character. The other was devised by Col. Parker Hitt, who was one of America's foremost cryptologists of the World War I era, for ITT, and involved ten cams with 96, 97, 98, 99, 100, 101, 102, 103, 104, and 105 positions, two of which supplied the bits to be XORed with one bit of the current plaintext character.
The XOR or exclusive-or logical operation is the simplest possible way to apply a key to a plaintext to conceal it. This operation is also modulo-2 addition, with the very small table:
| 0 1 ---+------- 0 | 0 1 1 | 1 0
If we view 0 as standing for "False", and 1 as standing for "True", then A exclusive-or B is true if either A is true exclusively (that is, A is true and B is false), or if B is true exclusively (B is true and A is false).
However, the machine devised by Vernam was modified to a form which was secure, and many countries have used similar devices. Instead of increasing the number of punched tape loops used to XOR with the plaintext, the number of key inputs was reduced from two to just one: and that one took a key tape consisting of completely random bits, used only once.
This, the one-time tape, is again the perfect case of polyalphabeticity, which was previously noted as the one-time pad under pencil-and-paper methods.
If anyone is unfamiliar with the alphabet used for 5-level teletypewriters, which is usually called the Baudot code, a table thereof is given here.
(In the interests of making complete information handy, the table included is one with some additional information from one of my USENET posts, since expanded with further additional information.)
Characters ITA 2 ITA 4 ITA 3 CCIR 476 FEC-A AUTOSPEC HNG-FEC ASCII
ITA 2 |US over
B F G S| AMTOR
R R E C|
I A R A|
Character 32 00000 100000 0000111 1101010 0001000 00000 00000 10001 00101 11110
Space 00100 000100 1101000 1011100 0000001 00100 11011 10101 01010 10111
Q 1 1 11101 011101 0001101 0101110 0111011 11101 11101 01100 01001 01111 Q 1 q !
W 2 2 11001 011001 0100101 0100111 0110010 11001 00110 01000 00110 00100 W 2 w
E 3 3 10000 010000 0111000 1010110 0100000 10000 01111 00001 10001 00101 E 3 e
R 4 4 01010 001010 1100100 1010101 0010101 01010 01010 11011 01000 00110 R 4 r $
T 5 5 00001 000001 1000101 1110100 0000010 00001 11110 10000 01100 01001 T 5 t
Y 6 6 10101 010101 0010101 0101011 0101010 10101 01010 00100 10111 11001 Y 6 y ^
U 7 7 11100 011100 0110010 1001110 0111000 11100 00011 01101 00000 11000 U 7 u &
I 8 8 01100 001100 1110000 1001101 0011001 01100 01100 11101 10100 00011 I 8 i
O 9 9 00011 000011 1000110 1110001 0000111 00011 00011 10010 11111 00111 O 9 o ~
P 0 0 01101 001101 1001010 0101101 0011010 01101 10010 11100 11101 10100 P 0 p
A - - 11000 011000 0011010 1000111 0110001 11000 11000 01001 01111 10011 A - a _
S ' BEL 10100 010100 0101010 1001011 0101001 10100 10100 00101 11110 01110 S ' s "
D WRU $ 10010 010010 0011100 1010011 0100101 10010 10010 00011 00010 01011 D d
F % É Ä Å ! 10110 010110 0010011 0011011 0101100 10110 01001 00111 01101 00000 F % f `
G @ % Ö Ä & 01011 001011 1100001 0110101 0010110 01011 10100 11010 00001 10001 G @ g }
H £ Ü Ö # 00101 000101 1010010 1101001 0001011 00101 00101 10100 00011 00010 H # h {
J BEL ' 11010 011010 0100011 0010111 0110100 11010 00101 01011 11100 11101 J * j
K ( ( 11110 011110 0001011 0011110 0111101 11110 11110 01111 10011 10110 K ( k [
L ) ) 01001 001001 1100010 1100101 0010011 01001 01001 11000 10010 11111 L ) l ]
Z + " 10001 010001 0110001 1100011 0100011 10001 10001 00000 11000 10010 Z + z
X / / 10111 010111 0010110 0111010 0101111 10111 10111 00110 00100 10111 X / x \
C : : 01110 001110 1001100 0011101 0011100 01110 10001 11111 00111 01101 C : c ;
V = ; 01111 001111 1001001 0111100 0011111 01111 01111 11110 01110 11010 V = v |
B ? ? 10011 010011 0011001 1110010 0100110 10011 01100 00010 01011 11100 B ? b
N , , 00110 000110 1010100 1011001 0001101 00110 00110 10111 11001 11011 N , n <
M . . 00111 000111 1010001 0111001 0001110 00111 11000 10110 10000 01100 M . m >
CR 00010 000010 1000011 1111000 0000100 00010 11101 10011 10110 10000
LF 01000 001000 1011000 1101100 0010000 01000 10111 11001 11011 01000
FIGS 11011 011011 0100110 0110110 0110111 11011 11011 01010 10101 01010
LTRS 11111 011111 0001110 1011010 0111110 11111 00000 01110 11010 00001
alpha (all 0) 000000 0101001 0001111 1000110
beta (all 1) 111111 0101100 0110011 1001001
SYNC 110011
repetition 0110100 1100110 1110000
CS1 1100101
CS2 1101010
CS3 1011001
International Telegraph Alphabet No. 5 is the international version of ASCII;
International Telegraph Alphabet No. 1 was a version of Émile Baudot's original 5-unit code, the one that included a 'letters space' and a 'figures space'. (I've seen a web site that incorrectly claims that International Morse, formerly Continental Morse, was ITA 1.)
International Telegraph Alphabet No. 2 is what is most commonly called Baudot; it is the 5-level code derived from the Murray code.
ITA 3 and ITA 4 are obscure, but they are both derived from ITA 2, as are a couple of other codes.
The final code, ten bits long, is AUTOSPEC. All the codes, except for CCIR 476, are shown in order of transmission; CCIR 476 is shown the other way around, being assumed to be sent LSB first as is ASCII. Also, the relationship of 0 and 1 to Y and B may be inverted for CCIR 476 as shown.
Unlike ITA 3, CCIR 476 has a pattern that relates it to ITA 2: except for the letters B and U, whose natural codes are used for alpha and beta, those ITA 2 characters which have 4, 3, or 2 one bits set are represented by 0x0, 0x1, and 1x1 respectively, where x represents the five bits of the ITA 2 character (in 54321 order); and 1nnnnn0 represents the characters that don't fit into this range, with again exactly 3 of the n bits set. Note also that ITA 3 is a 3 of 7 code, while CCIR 476 is a 4 of 7 code.
Perhaps this is why the newer CCIR 476 is the one US radio amateurs are permitted to use, and do use, for AMTOR, while the older ITA 3 was used for ARQ purposes originally. But it's odd to see a new code developed to fill exactly the same purpose as an older code already accepted as an international standard.
ITA 3 was known as, or derived from, the Moore ARQ code, also known as the RCA code. It appears to have been the first code used for ARQ (automatic repeat request) purposes, and to have been invented in or prior to 1946 by H. C. A. van Duuren. ITA 3 was adopted as an international standard in 1956, according to the source which first brought him to my attention.
IBM used a 4 of 8 code for transmitting the characters of a 6-bit code; this is illustrated below:
The first diagram illustrates the 6-bit characters being transmitted; the second diagram the actual 4 of 8 code by IBM. Then the third diagram illustrates an alternative coding that continues the symmetries evident in much of IBM's 4 of 8 code in what would seem to me to be a more consistent manner.
Note that six positions are filled with circles; those are the additional possibilities from the 70 provided by a 4 of 8 code not used for the 64 characters encoded; these were all used by IBM for special control functions.
AUTOSPEC repeats the five-bit character twice, but if the character is one with odd parity, the repetition is inverted. Thus, the parity bit is transmitted with high reliability, and every other bit of the character is effectively repeated twice. It can be thought of the result of applying an error-correcting code with the matrix:
1 0 0 0 0 0 1 1 1 1 0 1 0 0 0 1 0 1 1 1 0 0 1 0 0 1 1 0 1 1 0 0 0 1 0 1 1 1 0 1 0 0 0 0 1 1 1 1 1 0
to 5-level characters. (I have since learned that AUTOSPEC is one of two radio transmission modes that use this coding, and the coding itself is called the Bauer code.)
The other radio transmission mode that uses the Bauer code is SPREAD; in addition to using the Bauer code, it interleaves characters by delaying successive bits by 10, 20, or 50 bits, for an interleave of 11, 21, or 51.
HNG-FEC is also depicted here. Like AUTOSPEC, it is no longer in use; when it was used, it was only used by one nation, Hungary, for transmissions involving its embassies. These transmissions were apparently at 100.05 baud.
Each 5-bit character was encoded with 10 additional bits of error correction. In addition, the bits were interleaved on a 64-bit basis. This would help to protect against burst errors; also, note that 15 and 64 are relatively prime.
I am understanding that to mean that if the first bit of the first character transmitted is bit 1, and the first bit of the second character transmitted is bit 16, it is also the case that the second bit of the first character transmitted is bit 65 of the outgoing signal stream. So one can think of the bits as rotating between 15 groups, the bits in the first group containing the first bit of each coded character, the bits in the fifth group containing the second bit of each coded character delayed by 63 bits, and so on.
Had the interleaving been 61-bit interleaving, the delays would have been multiples of 60 bits, and thus the bits would have stayed in the same group, but since the mode was used to transmit coded messages, it did not matter if it was hard to understand.
The first five bits of the HNG-FEC code for a character are simply its ITA-2 code with the first and last bits inverted.
The code seems to be an error-correcting code with the matrix
1 0 0 0 0 1 0 1 0 0 1 1 0 1 1 0 1 0 0 0 1 1 1 1 0 1 0 1 1 0 0 0 1 0 0 0 1 1 1 1 0 1 0 0 1 0 0 0 1 0 1 0 0 1 1 0 1 1 1 0 0 0 0 0 1 0 1 0 0 1 1 0 1 1 1
followed by inverting some bits with the mask
1 0 0 0 1 0 0 1 0 1 1 1 1 1 0
In the error-correcting columns, there are two zeroes and three ones in every case except the second last column of the matrix, where there is only one zero.
Thus, if one were to remove the superfluous complexities from the code, and adapt it to be, like AUTOSPEC, more generally used, one might avoid using a mask to invert any bits, and use the following error-correcting matrix:
1 0 0 0 0 0 1 1 1 0 0 1 1 0 1 0 1 0 0 0 0 0 1 1 1 1 0 1 1 0 0 0 1 0 0 1 0 0 1 1 0 1 0 1 1 0 0 0 1 0 1 1 0 0 1 1 0 1 0 1 0 0 0 0 1 1 1 1 0 0 1 1 0 1 0
for a plain code with presumably equivalent properties.
However, inverting bits can serve a useful purpose. Thus, some SITOR modes involve repeating characters in inverted form; in situations where errors happen in only one direction, this allows a great many errors to be corrected.
Adding an overall parity bit as a sixteenth bit suggests itself. Indeed, there was a transmission mode used by Rumania that involved coding a 5-bit character in 16 bits.
The entries
F % É Ä Å ! and V = ;
mean that, for F, no figures shift character is defined by ITA 2; however, the % sign is used as a national-use figures shift character by Britain, É by France, Ä possibly by Germany (I am not completely sure of the order of the assignments), Å by Sweden (and apparently there is a common coding for the Scandinavian countries). The U.S. figures shift character is !. For V, however, the = sign is defined as the official figures shift character. The U.S. 5-unit teletypewriter code, which is nonconformant to ITA 2, defines ; as the figures shift character for V instead.
In fairness, it should be noted that the U.S. figures shift character set was developed when the Teletype Corporation first developed machines based on Donald Murray's principles, and ITA 2 was only developed later. And the semicolon and the double quote are more frequently used in normal typewritten texts than the plus and equals signs; the former are always included on English-language manual typewriters, the latter are often left out on models with smaller keyboards.
After the code bits, there are four more columns of characters, giving the characters used by ASCII over AMTOR. The all-zeroes character is used to toggle between the ordinary character set in the first two columns, and the auxilliary one in the second two. The ordinary character set is that of the international version of the 5-level code, rather than the U.S. version, but the figures shift of J, instead of being the bell, is the asterisk.
It was noted above that the code used for 5-level teleprinters is usually called the Baudot code. This is true despite the fact that the code originally developed by Émile Baudot in 1874 was completely different from the 5-unit code used in today's teletypewriters; this code is actually based on one later developed in 1901 in New Zealand by Donald Murray. However, the term "Baudot code" is used in a generic fashion for 5-unit codes in order to honor the original inventor of the principle of 5-unit telegraphy.
This pattern is followed elsewhere as well.
The code for transmitting chess moves by telegraph in the form of four-letter pronounceable groups is called the Uedemann code, for the first person to invent such a code, even though the code actually used is a later one, properly known as Gringmuth notation, because it was Uedemann who originated the basic principle, and Gringmuth supplied an improvement.
Many reference works contain tables of the American Morse Code and International Morse Code. It is the latter that is used even by American radio amateurs; the former was still used by American railways until quite recently. Usually, when people say "Morse Code", they are referring to the International Morse Code. But it is the American Morse Code that was actually devised by Samuel Findley Breese Morse (or perhaps his partner Alfred Vail). The International Morse Code was originally called the Continental Code, and it had a revision of Morse Code devised by the Austrian Friedrich Clement Gerke as its basis, but it underwent several significant revisions, including the addition of a code for the letter J, before what we now know as the International Morse Code was agreed upon in 1865, at the Paris International Telegraph Convention.
Thus, this is a general pattern: when a scheme for transmitting data is originated by an inventor, his name remains attached to the basic scheme, even when the actual code used has been subsequently modified by others. Even calling modern 5-level code "Murray code", as is sometimes done in Britain, is not strictly accurate, as some modifications were made to the code originally used with his equipment to arrive at International Telegraph Alphabet no. 2. This topic is dealt with in more detail at the web site of the NADCOMM Museum.
The reason that 5-level code is not so organized that when the letters are in alphabetical order, their codes are in binary numerical order, as is the case for ASCII, is because the codes were chosen so that the most common letters would have codes that would cause less wear and tear on the moving parts of teleprinters. The following chart shows the scheme by which the codes were assigned:
---- line feed
|
| --- space --- letters shift
|| |
|| -- carriage return | -- figures shift
||| ||
E|||T AINO UCM KV SRH DL FG TP BW QX ||YZ
1 * * * * * * * * ** ** ****
2 * ** ** ** * * * ** * * **
3 * ** *** ** * * * * ** * *
4 * ** ** ** * * ** * * * **
5 * * * * * * * * ** ** ****
The bits are numbered from 1 to 5, in the order in which they are transmitted. They are normally preceded by one start bit (0) and followed by one and a half stop bits - that is, a 1 level on the wire for one and a half times the time used for transmitting a data bit. In ASCII, the bits of a character are transmitted least significant bit first; since the 5-level code bits don't represent codes in any kind of numerical order, sometimes bit 5 and sometimes bit 1 is taken as the most significant bit, although the tendency has been to treat bit 5 as the MSB because of the use of the same UART chips for ASCII and 5-level code.
And here is a graphical version, showing the standard, U.S., financial, and weather character sets:
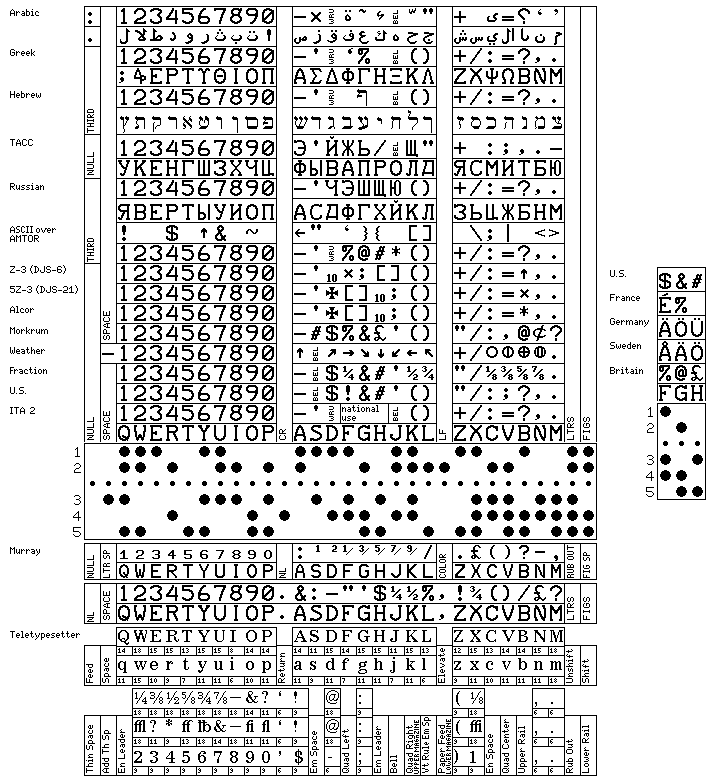
The top two lines show one of the methods used for transmitting the Arabic language with 5-level code, and the next two show that used for Hebrew.
A later pair of lines show the version of the 5-level code used for the Russian language. The code 11111 shifts to the Latin alphabet, and the code 00000 shifts to Cyrillic characters, as it is given in the article on "Codes" in the Great Soviet Encyclopedia. The code as shown omitted the hard sign, which can be replaced by the apostrophe as needed, the letter E surmounted by an umlaut, which indicates palatalized O, and which is often not used, and the very common letter signifying "ch". In the diagram above, I show that last letter where my reference shows the WRU control code.
I have seen a different Russian 5-level code, where characters common to the Cyrillic and Latin alphabets are not duplicated, for use with an early Russian computer system; this made extra characters available for use in programming. Unfortunately, I no longer have access to the source where I saw it; I believe it may have been for the Minsk-22 computer system.
There may be a defined French coding for the figures shift of H, although my source showed that not used; I am not sure of the ordering of the three umlaut characters for Germany. Thus, what you see above is somewhat of a working drawing rather than something finished and definitively accurate.
The Alcor coding above is from Dik Winter's page, mentioned below; here, the Maltese cross typewheel symbol used for unused characters on some teleprinter elements was left in, as seen on his page, for the position used for WRU; perhaps it was used as a printing character to indicate reserved words or composite symbols needed for ALGOL programming in addition to those shown.
Above the Alcor coding, the coding used with the model Z-3 teletypewriter, as connected to the DJS-6 computer in the People's Republic of China, and also designed for use with ALGOL-60, is shown, as well as that for the model 5Z-3 teletypewriter, as connected to the DJS-21 computer. This code matches the ALCOR coding, except for using a multiplication symbol instead of an asterisk; it was an international standard, DIN 66006, in use in Europe, so this is not surprising.
Below the Alcor coding, a historical coding, earlier than that used on 5-level Teletype machines, but later than the Murray code, is depicted; this code was used on the Morkrum printing telegraph according to a thesis. However, the period is not included in the character set. Also, some very early specimens of the Morkrum Printing Telegraph offered the "Blue Code", which provided for lower-case letters; as yet, I have not been able to locate details of this.
Below the image of a tape showing the form of the binary codes, the top two lines show the original Murray code, from which the modern 5-level code is derived. (The original Baudot code was completely different.) It too, like the original Baudot, used a letters space and a figures space.
Originally, I had speculated, since my only source for the original Murray code was secondary, that the shift of A might be a comma, but I have since seen a more definitive source in which that position was still blank. In both of those sources, the shift of M was the single quote. A third source, which I now follow in the illustration, gives the shift of A as the colon, and the shift of M as the comma.
Two later lines depict a later version of the Murray code, which used the modern figures shift and letters shift characters, described by Donald Murray in a paper appearing in 1905 in the Journal of the Institution of Electrical Engineers. In this code, though, the all-zeroes character was used to indicate a new line, so that the modern CR and LF chracters could be used for two additional printable characters; thus, the comma and period could be on separate keys as on a typewriter.
Five lines are used to show the six-bit coding, based on 5-level code, used for Teletypesetter equipment, once commonly used in newspaper typesetting.
To the right of the main diagram, the way in which the National Use positions in ITA 2 are assigned in several countries is shown. In addition to the assignments in the United Kingdom, France, Germany, and Sweden, a set is also shown for the United States. This was used, for example, in the Texas Instruments Silent 700 model 732 thermal printing terminal; thus, while the single quote and the bell were swapped on U.S. mechanical teletypewriters compared to those which followed ITA 2, later electronic ones followed ITA 2 while retaining as much of the older coding as possible ($ was moved from being the shift of D to being the shift of F, while & and # retained their old positions).
The diagram below shows the teleprinter code used for the Thai language.

This diagram is based on two sources, neither of which was fully legible to me, and which partly contradicted each other; as well, it was constrained by a third source for the Thai character set. Thus, it contains some omissions, and has been biased towards an older type of Thai teleprinter instead of the current official standard, TIS 1074, as depicted in my main source, the home page of Dik Winter, even if I did choose to favor the older but less helpful source that seemed to be more closely based on an actual teleprinter back in the days when mechanical teleprinters were likely to have been in actual use in Thailand to an extensive degree. The standard was adopted officially only much later. It is, at least, legible; the Thai characters indicated are drawn in sufficient detail to be unambiguous in their appearance.
It is similar to the 5-level code in that the characters CR, Q, and W have the same codes, and the middle shift has the same code as LTRS, and the lower shift has the same code as FIGS, but those are the only matching characters. One suspects that codes were allocated here on the basis of minimizing wear and tear based on Thai symbol frequencies, and then the letters of the Latin alphabet were simply placed on the keyboard in the conventional QWERTY arrangement, associated with the Thai letters in their conventional positions on Thai typewriter keyboards.
This is the opposite of what happened with Russian, where letters were assigned on the basis of a convention of transliteration; the Russian typewriter layout is very different from the standard English QWERTY layout, but Russian 5-level teletypes have to be laid out in the QWERTY arrangement so that the ten digits will be in order.
5-level code is still used, not just by radio amateurs, because over the radio bandwidth is limited, particularly in the lower frequencies, which have desirable properties (i.e., not being limited to line-of-sight, like TV and FM radio).
It can be transmitted by directly keying the carrier on and off, or by transmitting an audio signal with different frequencies for mark and space by AM radio (AFSK, audio frequency shift keying), or by more complicated methods.
A fictitious example is shown below:
------------------------------------------------------------------ | First tone | | | combination (Hz) |-----------------------------------------------| | | | LF | L | C | G | | | 437 551 | alpha | 01000 | 01001 | 01110 | 01011 | sync | | |-------+-------+-------+-------+-------+-------| | | H | space | T | N | M | CR | | 437 703 | 00101 | 00100 | 00001 | 00110 | 00111 | 00010 | | |-------+-------+-------+-------+-------+-------| | | c. 32 | I | P | R | V | O | | 437 817 | 00000 | 01100 | 01101 | 01010 | 01111 | 00011 | | |-------+-------+-------+-------+-------+-------| | | U | E | Y | D | B | LTRS | | 551 703 | 11100 | 10000 | 10101 | 10010 | 10011 | 11111 | | |-------+-------+-------+-------+-------+-------| | | Q | A | W | K | FIGS | J | | 551 817 | 11101 | 11000 | 11001 | 11110 | 11011 | 11010 | | |-------+-------+-------+-------+-------+-------| | | | S | Z | F | X | | | 703 817 | (bad) | 10100 | 10001 | 10110 | 10111 | beta | |------------------|-----------------------------------------------| | | 437 437 437 | | | 551 551 551 | | | 703 703 703 | | | 817 817 817 | | | | | | Second tone combination (Hz) | ------------------------------------------------------------------
This coding has the property that if one complements the bits of a character, the tone combinations that represent it also have exactly the opposite frequencies. Each 5-level character is represented by two successive frequency combinations chosen by a 2 out of 4 code.
The frequencies of the audio tones are the 23rd, 29th, 37th, and 43rd multiples of 19 Hz, thus reducing harmonic interference. The tones lie within a single octave, simplifying circuitry to handle them, and they are separated by at least 114 Hz from the adjacent tone, allowing them to be modulated by signals with a bandwidth of up to 50 Hz, allowing 100 states per second or 50 characters per second with plain pulses, or 32 states per second or 16 characters per second with third-harmonic pulse shaping. Of course, if this is considered a modulation method applied to a 627 Hz audio subcarrier, it ought to be possible to use a signal with a bandwidth of up to 200 Hz while still limiting the overall transmitted signal to a 2 kHz channel. Decoding would become more complicated, however, and noise immunity would be lost.
The 16 code combinations in the center square of the code have a particularly simple structure:
Bit 3 is chosen to maintain the symmetry, and to place most of the control characters outside the simple center area, and the most common letters within.
The position of the character corresponding to a character in the middle square, but with the middle bit complemented, follows a simple pattern as well, which the left half of this diagram illustrates:
4 5 6 7 o e o o 1 0 1 2 3 2 e O O E O o 0 4 5 6 7 3 e E O E E e C 8 9 A B F o O O E O o D C D E F E e E O E E o 8 9 A B e e o e
showing the hexadecimal code resulting from removing the middle bit of the 5-bit character; and the right half of the diagram shows the distribution of even and odd parity among the characters.
Incidentally, the real transmission mode which people who monitor utility broadcasts as a hobby call PICCOLO involves using two consecutive tones, each having six possible frequencies, to represent a five-bit character. And the idea of representing five bits by the cells of a 6 by 6 square missing its corners is also used in one of the forms of trellis-code modulation used with v.32 modems at 9600 bits per second.
The five bits are used for four data bits and one parity bit, and the modulation rate is 2400 baud, which means that, given one start bit and one stop bit, a "9600 baud" modem would actually be capable of handling, on the input of its serial port, a 12,000 baud serial data stream, I would have thought, since the higher-speed modems do not send the start and stop bits. However, they may face other overhead for synchronization purposes, since the standards do specify more than just a modulation method.
On another page, I discuss a current official standard for using lower case with 5-level code, CCITT/ITU Recommendation S.2, which uses extra LTRS characters while in letters shift to switch between upper and lower case, and I also propose ways to extend 5-level code to embrace the entire UNICODE character repertoire.
At the moment, I don't have another page on which to note this; here, we have seen that the 32 characters in 5-level code can be represented by either a 3 of 7 code or a 4 of 7 code. Thus, a 4 of 8 code, with 70 possible characters, can be used to represent 6 bits in a DC-free signal with modest overhead; IBM used one such code for some of its computer interfaces.
A 5 of 10 code allows 252 possible symbols. This falls just slightly short of 256. If one imposes additional restrictions in order to have frequent transitions for good clocking, and in addition allows some bytes to be encoded, alternately, by either a 4 of 10 code symbol or a 6 of 10 code symbol, one has a code similar to the 8B/10B code currently used in the new Gigabit Ethernet standard.