Under what conditions can one say that a cipher is unbreakable, or even that it is adequately secure?
This is an interesting question, even if, in practice, any answer is likely to be deceptive. An attacker seeking to eavesdrop on someone else's communications is not limited to gentlemanly rules or to expected attacks. As we have seen in the section on block ciphers, resistance to a ciphertext-only attack is not considered enough: a block cipher is held to be weak even if it is only possible to deduce the key by enciphering vast quantities of chosen plaintext on the equipment of the person whose communications are to be read. From the viewpoint of the original military applications of cryptography, it would seem that, if one has such access, why not just plant a bug?
But if a cipher is secure against such attacks, then it can be used for other applications: for example, encryption can be provided as a kind of public utility, protecting terminal to computer communications in a time-sharing environment. Also, using a block cipher as a component in a hash function may be safer.
Even more important, the boundaries between a ciphertext-only attack, a known plaintext attack, and a chosen-plaintext attack are not necessarily rigid in practice. One of the techniques used to mount a ciphertext-only attack on a message is the probable word method, where a guess about possible plaintext is tried as a hypothesis. This, in effect, at the cost of some wrong guesses and additional trials, turns the ciphertext-only case into the known plaintext case. Similarly, if a sufficient amount of known plaintext is available, that quantity will include plaintexts with different properties, including some that are desirable to the cryptanalyst; hence, at least in extreme cases, the known plaintext case blurs into the chosen-plaintext case.
The one-time pad is an example of a cipher system that can be seen to be unbreakable.
This is because a key, having the same length as the message, is used only once, on that message, in such a way that, because the key is random, any other message having the same length as the message seen is entirely possible as far as someone not knowing the key can possibly determine.
The requirements for this are:
If it were possible to subject messages, before encipherment, to perfect compression, so that any string of letters would be a valid, sensible, message, then any conventional encipherment scheme would be partly unbreakable. If there were a million possible keys, then there would be a million possible messages, all equally reasonable.
When the message is longer than the key, some information about the message is still gained, because the possibilities will be narrowed.
In practice, with normal text messages, that kind of compression is not possible. The messages decoded by trying wrong keys might come close to making sense, but they could not all be perfectly reasonable, and in fact it's highly unlikely that any doubt about the correct message could really exist. But if the message consisted only of random numbers to begin with, for example, a session key transmitted under a key-exchange key, this does point out a case in which a conventional cipher becomes resistant to attack.
The fact that a message consisting only of random numbers, enciphered by a conventional cryptosystem, cannot be broken, since there is no way to choose between the plaintexts that different keys produce in that case (in the case of a public-key cipher, on the other hand, one can decide which is the correct decipherment) has led to a type of cipher system being proposed that, while it has some interesting properties, is not completely unbreakable. However, because it is based on individual messages, each of which (in isolation) is completely unbreakable, people have occasionally become confused by the fallacy that the system as a whole is unbreakable as well.
The simplest case is the following:
Let us encipher a message by applying a sequence of random data to it after the manner of a one-time-pad. The result of this is cipher message A, which, without knowing the random data, is unbreakable.
Let us then also transmit cipher message B, consisting of the text of the one-time-pad, enciphered in some fashion.
This system was once proposed in the pages of the journal Cryptologia, in an article that claimed it was a simplified or modernized version of the Aryabharata cipher of ancient India.
Neither message A nor message B can, in isolation, be broken by a cryptanalyst. But since both messages are being transmitted, both messages can be intercepted. Thus, working on the two messages together, a cryptanalyst may be able to make some progress.
If message B were enciphered using only monalphabetic substitution, admittedly an extremely simple case, the method of attack on such a system can be given. All the letters in message A that correspond to any one letter of the alphabet as it repeats in message B were enciphered by a single (but unknown) letter in the one-time-pad, and a frequency count is sufficient to solve a Caesar cipher.
Sending both a message enciphered by a random OTP and the random OTP itself is, essentially, a way of splitting a message into two parts, each of which are random in themselves. The next step above the relatively weak system just discussed would be to encipher message A by some system as well. While no theoretical immunity to cryptanalysis is gained, it may well be true that cryptanalysis by establishing correlations between two messages, each enciphered in a different way, is more difficult than solving a message that has simply been enciphered twice, by the use of each system in turn.
For example, if the two methods used are the Playfair cipher and simple columnar transposition, if transposition is used first, the Playfair cipher can still be attacked, because it takes each input letter to a limited number of substitutes; if the Playfair cipher is used first, multiple anagramming, although now much more difficult, is still possible because a text enciphered by Playfair still has digraph frequencies marked well enough to allow a correct match to be detected.
But if what we have is a random OTP, enciphered by simple columnar transposition, and the message, first with the OTP (before transposition) applied, and then enciphered by Playfair, then it is not at all clear how we can apply techniques analogous to those used against these two ciphers in the double encryption case.
Since the enciphered OTP, being transmitted, is known, one might, however, consider the following arrangement, which involves sending only one message, to be equivalent: take a fixed random sequence of letters (perhaps derived from the digits of pi; since we're using Playfair, we need a 25-letter alphabet anyways), then encipher (or, to be strictly equivalent, decipher) it using the current key by simple columnar transposition, apply the result by Vigenere to the plaintext, then encipher the result with Playfair.
The main difference between that and double encryption is the presence of a fixed random sequence. Thus, it would seem that message splitting only provides additional strength by hiding statistical properties of the plaintext, whch is only of benefit against weak or poorly designed ciphers.
Even so, a still more elaborate form of message splitting suggests itself. A base station could send, to a remote station, a thousand pads of random data, each one accompanied by an identification number, protected by one form of encryption.
Then, the remote station could, to send a message back to the base station, select two of those pads to use (and then discard), sending a message, also encrypted by a different key and cipher method, consisting of the numbers of the two pads chosen, the starting points within them, and then the message with the two pads applied.
The messages sent in both directions are enciphered random data, impossible to break individually, but now it is also not possible for the cryptanalyst to determine which three messages to attempt to correlate with one another, or at what starting points. This still isn't unbreakable in theory, but it certainly does seem like it would make things considerably more difficult for an attacker. Although such a method, as it increases the amount of bandwidth required for sending a message by a factor of three, as well as requiring a lengthy amount of transmission in advance, would seem to be impractical, it may be noted that some military communications systems transmit encrypted data continuously, even though the actual message traffic being sent is much smaller, in order to prevent an eavesdropper from gaining information on how much is being communicated and to whom. Attempts to gain this kind of information, falling short of actual message contents, through eavesdropping, are known as traffic analysis. In such a case, instead of leaving the extra capacity of the channel entirely unused, it could be used to send random superencipherment pads during the time when no messages are being sent. Such a channel might work as shown in the diagram below:
While the idea of sending superencipherment pads during otherwise idle time may not have been used, it is likely that encrypted channels resembling what is shown in the diagram in part may have been used in practice.
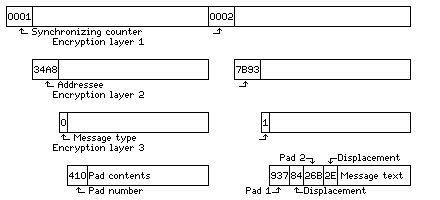
To allow the reciever to keep track of where packets begin and end, a counter field is shown. A special synchronization signal, not corresponding to any binary data value, might also be used, as it may not be necessary to label each packet uniquely. In any case, as the counter contains no information, but is a fixed sequence, it is shown as not encrypted.
Encryption layer 1 is some method of encryption shared by the entire communications network. This is used to conceal everything about the packets being sent, and thus it blocks traffic analysis.
Beneath that layer, only the addressee is not otherwise encrypted. Different groups of addressees may use even different encryption algorithms in addition to using different keys.
Encryption layer 2 is unique to each addressee; each one has a unique key, and different addressees may even use different algorithms in some cases. Some addressee codes, however, may correspond to messages intended for more than one recipient, in which case all those recipients would share the necessary key.
At this point, the information which identifies a block as either an encrypted message or a pad of random data is in the clear.
Encryption layer 3 consists of the two different algorithms used by each recipient, one for the superencipherment pads, and a completely unrelated one for messages. Using unrelated algorithms is an important step in allowing the random data to be used to make cryptanalysis more difficult.
Finally, the actual pads, labelled with their identifying numbers, are visible in unencrypted form. The plaintext messages are still encrypted, but only by addition of two pads, the identification numbers of which, and the starting points used in which, appear at this stage in the clear without further encryption accompanying the plaintext message.
However, the scheme as illustrated above is not quite practical. Three layers of encryption are not really necessary, and sending each of possibly 65,536 addressees their very own set of 4,096 superencipherment pads is rather excessive. A modified version of this scheme more suitable to actual implementation is illustrated below:
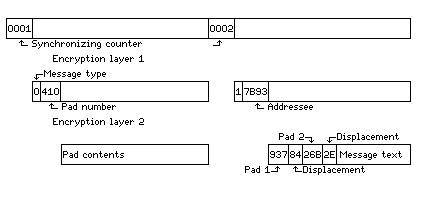
Here, removing the first layer of encryption, common to the whole network, immediately reveals whether a block is a keypad or a message. The identification number of each keypad and the addressee of each message is also revealed; note that keypads do not have addressees.
The second layer of encryption is unique to each addressee, at least in that each addressee has a unique key. Different classes of addressee may also use different algorithms. Also, once again, each addressee uses one algorithm to decrypt keypads, and a completely different one to decrypt messages.
In this fashion, the hub of the network only requires one set of 4,096 keypads, but the keypads are "decrypted" in a different way by each addressee (and by the hub for communicating with that addressee).
Note that the displacement and pad number within a message must be random, and so keypads must be exactly 256 elements long in the format shown. If an element were a hexadecimal digit, or nybble, instead of a byte, we could say from the diagrams that in the first format the message text field would be 249 nybbles long, and in the second it would be 245 nybbles long. In an actual format, however, keypads would probably fill more than one block, and the number of blocks in a message would be variable. If there were fifteen allowed message lengths in blocks, this would work out nicely in using a single hexadecimal digit to indicate the start of either a keypad or a message, and in the case of a message, also its length.
It should be noted, though, that, if it is assumed that the first layer of encryption, since it is shared among all the nodes in the network, can be compromised, then the fact that the keypad numbers are not further concealed does weaken this system: for each value tried in a brute-force search of the key for a message block, the related keypad is immediately identifiable. One still doesn't know which one is the right one, but one of the points of uncertainty is lost.
If the whole keypad, including the keypad number, was encrypted by most reasonably secure methods, then there would be no assurance that a complete set of keypads was recieved by any node. One way of solving this would be to give each node its own codebook with 4,096 entries for interpreting the keypad numbers in its own way.
One could also do this: usually just send out random bits for keypads, which will be treated by each recieving node as an encrypted keypad including an identification number which is also covered by the encryption, but also decrypt these keypads that are sent out for storage (as would be required anyways) using the keys of each node. Then, monitor if for any node, any of the keypad numbers is excessively stale: if so, using that keypad number, followed by random bits, create a keypad block by enciphering it using the key for that particular node which needs a fresh keypad of that number.
Another idea, which I feel is related to the form of message splitting examined above, has recently been suggested by Douglas A. Gwyn in the sci.crypt newsgroup.
In many cryptosystems, a higher-security cipher with a longer key is used for the occasional exchange of new keys used for the cipher system that is used for the actual protection of plaintext.
What was suggested was that keys be exchanged much more frequently; instead of taking into account how difficult the cipher being used is to break, use new keys so frequently that if the keys were safe from attack, no unambiguous decryption of the text encrypted under only one key would be possible. If the plaintext was well compressed, this could be achieved while transmitting somewhat less key material than plaintext.
A later extension of this proposal involved adding message splitting to the system by sending a random mask as the first plaintext block, and then performing an XOR between it and the plaintext of each succeeding block as the first step in that plaintext's encipherment.
This, like message splitting, does force the cryptanalyst to work on two separately keyed blocks at once, and thus it has some value, but I am not sure of exactly how much value. Unlike message splitting, though, this does not double bandwidth consumption, and unlike double encryption, it does not require twice as much work to encrypt a message.
I found it sufficiently interesting to propose the following elaboration of it, which does require as much time to encrypt a message as does double encryption, though:
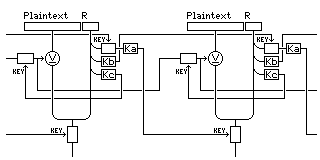
Use the key that comes with each message block, and encrypt it with three different keys to obtain three keys used for different purposes.
A changing key encryption key, followed by a second encryption with one of the three fixed keys, obtains the key for encrypting the next block.
The second fixed key obtains the key encryption key for the next block.
The third fixed key obtains the key used to encrypt the mask, as used with the previous block, to use with this block.
In this way, the keys for encrypting blocks aren't sent encrypted in exactly the same way as the plaintext, but are protected by an extra layer of encryption. In addition, having the mask constantly changing increases its effectiveness.
In detail, this scheme works as follows:
Initial keys:
First block:
E(P1, KA1), where the first plaintext message P1 is composed of R, random data 896 bits long, and K2, a 128-bit random vector.
Set:
Second block - and subsequent blocks follow the same pattern:
E(P2, KA2), where P2 is composed of 896 bits of plaintext sent in this block, XOR M2, and K3, a 128-bit random vector.
Set:
Thus: each block consists of 896 bits of plaintext and a 128-bit random vector which is used as a source of keys.
First, the block is deciphered by the current regular key (KA2).
This obtains the plaintext XORed with the current mask (M2), and it obtains the key source value.
The key source value (K3) is used to generate three keys.
Some additional discussion of ideas suggested by the "Aryabharata" cipher is on this page.
However, the limitation to cryptanalysis discussed above, that if a plaintext has no non-random distinguishing characteristics, there is no way to determine if a decryption key being tried is really correct, does not apply to public key systems. There is no conventional secret key in a system like RSA. There is a private key, which is very difficult to deduce from the public key: but it is still a fact that, if one had enough computer power available, the public key strictly determines what the private key must be. Thus, knowing the public key means that there is only one way to decode a message sent with it.
From the information-theoretic perspective, therefore, which does not attempt to estimate the limits of an adversary's computational and analytic ability, only the one-time pad is truly secure, and public-key cryptography is completely worthless!
However, that perspective is not the whole story. The other half of cryptographic security, called the "work factor", by Claude Shannon, refers to the difficulty of either trying all possible keys, or of doing something better, to read a message. But in this area, it is no longer possible to set definite limits to cryptanalysis, since no one knows, for example, what new methods of factoring large numbers might be discovered tomorrow.
Relying on the "work factor", rather than on the information-theoretic absolute limits, lets one have the convenience of a short key that one can change at leisure (with conventional encryption), or the additional convenience offered by public-key systems. But it has a price: one no longer has a way of proving how truly secure one's messages are.