In the preceding sections, we have seen ways to convert a message consisting of binary bits into either base-26 or base-10 for transmission. Since it is intended that the message ultimately be read by its legitimate recipient, it is necessary that the conversion be invertible.
People working with simulation problems on computers have developed techniques for base conversion that are simplified because they do not need to take this constraint into account.
One could have a standard pseudorandom number generation routine, and it might produce numbers from 0 to 32,767 each time it is run. And for a particular problem, one needs uniformly distributed integers from 0 to 922.
The simplest way of doing this is to note that 15 times 923 is 32,305. So, when you generate a pseudorandom number, if it is from 0 to 32,304, take the remainder when it is divided by 923 as your number from 0 to 922, otherwise, discard the result.
This isn't invertible, as more than one sequence of numbers from 0 to 32,768 will lead to the same sequence of numbers from 0 to 922, but that is not a concern for such an application. But because it throws away information, it is somewhat wasteful: particularly worrying is the chance of a long run of pseudorandom numbers from 32,305 to 32,767, which could cause delays.
Essentially, when a number is generated, a random number from 0 to 34 is being thrown away, and when one is not being generated, a number from 0 to 462 is being thrown away. One can improve the efficiency of the conversion process by keeping these numbers, and treating them the same way, in essence, as we treated the output of our binary pseudorandom number generator.
To illustrate this technique with a more useful example:
Let's say you want to convert a stream of random bits into uniformly distributed numbers from 0 to 999.
Then, you start by taking the bits 10 at a time to give you a number from 0 to 1023. If that number is less than 1000, you've got a number. (Note that here one does not have a multiple of 1000, so there is nothing to save when a number is generated. In general, this will always be true if we start from a stream of bits which we can use in groups of any size, since if we are using enough bits to give us a number twice as large as the desired number, we are using one bit too many.)
Otherwise, subtract 1000 from the number, to give you a number from 0 to 23. Treat that as a base-24 digit, and introduce it into another accumulator (acc = acc*24 + new_digit) that holds numbers up to 24^3, or 13824.
When this has happened three times, if the number in the accumulator is from 0 to 12999, take the last three digits as your number.
If you want, you can now repeat the process by taking the first few digits, as a number from 0 to 12, and therefore a base-13 digit, and save them in an accumulator; and, if you get a result you can't use, a number from 13000 to 13824, you can subtract 13000 and save that result as a base-824 digit.Since 1000 is a multiple of 8, however, we could simplify the process, at least by requiring smaller accumulators for the calculations, and thus potentially avoiding multiprecision multiplications, by modifying it as follows: take the stream of bits seven bits at a time, and convert it into numbers from 0 to 124, that is, base-125 digits. When the process has successfully produced such a number, then take three more bits from the keystream to make it a number from 0 to 999.
The process for that case follows the same scheme as the direct process for producing numbers from 0 to 999, but because the omitted powers of two change the size of the numbers involved, an exact analogy between the digit sizes involved breaks down at later steps.
Take seven bits from the keystream, giving a number from 0 to 127. If that number is from 0 to 124, it is the result. Otherwise, subtract 125 from the number, giving a number from 0 to 2. Introduce this base-3 digit into an accumulator that holds numbers up to 3^5, or 243.
When that accumulator has 5 digits in it, it contains a random number from 0 to 242. If it is from 0 to 124, accept it as the result. Otherwise, subtract 125, and put the resulting number, from 0 to 117, in another accumulator, and so on.
Where you want to stop, and just throw away unusable results, depends on how efficiently you want to convert the random bit stream to a random digit stream.
This can certainly be used in cryptography to allow a binary stream cipher to encipher a plaintext composed of digits into a ciphertext also composed of digits.
If one is enciphering binary plaintext to binary ciphertext, one could use two keystream generators, for example, one designed to produce pseudorandom base-7 digits from 0 to 6, and another designed to produce pseudorandom base-23 digits from 0 to 22, independently converting the outputs of each to, say, base 256 using the technique given above, and using the XOR of the two converted keystreams on the plaintext. The use of two different bases to produce binary bits, which are then combined in the binary world, would make many forms of analysis much more complicated. However, this type of cryptography is vulnerable to timing attacks and related techniques such as monitoring the power consumption of a chip, because sometimes extra steps are required to produce the output in a new base.
The techniques outlined here are closely related to techniques used to remove bias from a physical source of random bits.
If a physical source of randomness provides bits which are not deterministic, and which are uncorrelated, but which may have a degree of bias, so that the probability of one of the outputs is slightly higher or lower than 50%, perfect random bits may be obtained from it by the following technique, due to John von Neumann:
Interpret the bits in pairs as follows:
00: ignore 01: produce 0 10: produce 1 11: ignore
Incidentally, the implementation of this technique in hardware has recently been covered by a patent associated with the support devices for the Intel Pentium III chip.
The efficiency of this can be improved by generating additional independent random bits by using the 00 and 11 strings as if they were 0 and 1 bits from a somewhat more biased physical source, which is exactly what they are. And this can be cascaded by using the 00 and 11 at the next level, due to 0000 and 1111 from the original stream, in the same way.
A further improvement, which is easy to overlook, produces a technique which has been mathematically proven to have the best possible efficiency in producing genuinely random bits from a biased, but otherwise perfect, physical source of randomness. At each level, whether a bit is immediately produced (from 01 or 10) or whether a combination is promoted to the next level (from 00 and 11) constitutes an additional random, but biased, bit which may also be subjected to the same processing as the original bits from the physical random source.
This technique is known as Peres unbiasing, after its inventor.
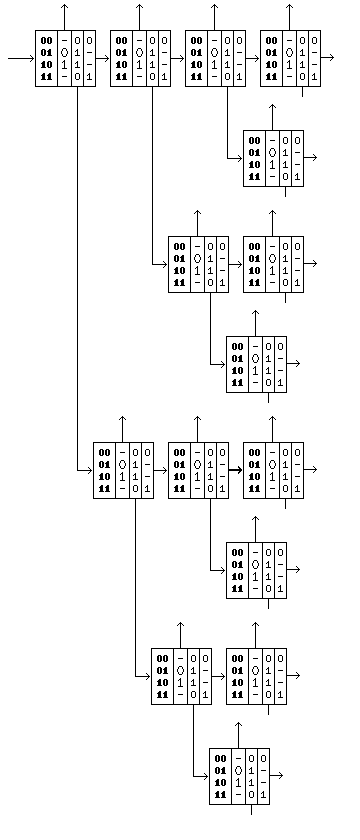
This algorithm is, of course, recursive in nature, which naturally makes it more difficult to understand, but the diagram at the right may help. A source of random bits is shown entering from the left in the upper left corner of the diagram. Each stage in the cascade outputs perfect random bits upwards, bits to be processed at the next level to the right, and the additional type of bits which distinguish Peres unbiasing downwards.
The cells in the diagram may be understood as tables in the following form:
INP UNB PAT NEX
00 | -- | 0 | 0
01 | 0 | 1 | --
10 | 1 | 1 | --
11 | -- | 0 | 1
where the significance of the columns is as follows:
If the source of input bits were unbiased, note that on average for every four bits of input, there is one bit of unbiased output, and one bit of next-level output, but two bits of pattern type output. Thus, adding the pattern type output is very important, because it is twice as significant as the next-level output. And since the total number of output bits, for an unbiased input stream, is the same as the number of input bits, it can be seen that it is at least plausible that Peres unbiasing could be the best possible scheme.
In the case where the input bits are unbiased, the only other thing that needs to be proven is that all the input bits would, as the algorithm proceeds to infinitely high level of recursion, eventually end up as output bits. Each cell in the diagram produces 25% of its input as final output, and since the limit of .75 raised to the n-th power, as n approaches infinity, is zero, maximum efficiency is proven for that case.
Where the input bits are biased, if the algorithm is perfectly efficient, the expected number of output bits should equal the entropy in bits of the input sequence.
The formula in information theory for the entropy in bits of characters from any alphabet is:
n
------
\ / \
\ | 1 |
> p * log | ----- |
/ i 2 | p |
/ \ i /
------
i = 1
This formula is understandable from how data compression works. For example, the table below:
A 25% 00 B 25% 01 C 50% 1
illustrates an alphabet of three characters, with their probabilities and an obviously maximally-efficient binary coding for them. The number of bits consumed by this coding, applied to K characters of this alphabet, is clearly K times ( .25 * 2 + .25 * 2 + .5 * 1 ), which is K times what the formula above calculates.
Let us now look at the inputs and outputs from a single cell in Peres unbiasing.
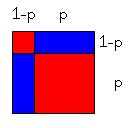
Let the probability of a 1 in the input to the cell be denoted by p; then the probability of a 0 is 1-p.
The input consists of two bits with probability distribution (1-p, p). The entropy of those two bits is 2*((1-p)*log2(1/(1-p)) + p*log2(1/p)).
The output consists of three kinds of bits.
With probability 2 * p * (1-p), an unbiased bit is output as a bit of the target unbiased final output. This bit has entropy 1, of course; and so the total entropy output via this channel is 2 * p * (1-p).
There will always be a pattern type bit output from the cell; the probability that both input bits are the same is p * p + (1-p) * (1-p), or 2p^2 - 2p + 2.
A next-level bit is output from the cell with probability 2p^2 - 2p + 2, therefore, and the probability that it is a 1 is p*p, and the probability that it is a 0 is (1-p)*(1-p).
Given this, all we need to show is that each cell, for all values of p, is entropy conserving. Remembering the basic property of logarithms, that log(a)+log(b) equals log(a*b), the rest is algebra.
Incidentally, while the outputs from the individual cells in the diagram all constitute sources of unbiased and random bits, there is a potential pitfall which implementors of Peres unbiasing must avoid. If a sequential implementation of this algorithm were to delay the output from one cell, relative to that from another cell, based on whether that output was 0 or 1, that could introduce bias into the bit stream resulting from combining the outputs of all the cells, even though the individual cell outputs were random and unbiased.
Normally, this particular problem would be too obvious for words; since the goal is to produce unbiased random bits, of course it is necessary to treat 0 and 1 the same way when they are produced as output. However, note that the new and nonobvious output bit which distinguishes the Peres unbiasing algorithm, the pattern type output, is accompanied by a next-level output when it is a 0, but is not so accompanied when it is a 1.
That could result in this internal bit being delayed when it is a 1, but not if it is a 0, if next-level bits are processed before pattern type bits, and the temptation to do so is strong, because the next-level bits are a more obvious component of the algorithm.
There are, of course, many different ways to combine the output bits, and order the operations, in this algorithm that do not have this problem.
The problem only exists because the cells in the diagram may, when they recieve the second bit of a pair of bits as input, output two bits at once in different directions, a next-level bit in addition to a pattern type bit. It may be avoided by processing pattern type bits first, and it can also be avoided by buffering the unbiased output from each cell individually, and collecting these outputs in a fixed order through the cells after the processing of a fixed number of input bits.
A question which may occur, based on the claim that Peres unbiasing is perfect, is whether or not it may be used as a form of data compression when applied to an input bitstream. Of course, the simplest method of compressing an input stream of biased bits is arithmetic coding; and it seems as though Peres unbiasing could not be reversible, since it is never clear where any output bit has come from. Some loss of information in the Peres unbiasing of any finite stream of biased bits is entirely consistent with the perfection of Peres unbiasing, since the final state of the network of unbiasing cells is not part of the output of unbiased bits, representing a loss of information that tends to insignificance as the number of bits being unbiased becomes larger.
Given that each cell always produces a pattern type output, and recognizing that some sort of overhead that tends to zero proportionately as the number of bits being compressed tends to infinity will be required, a data compression scheme based on Peres unbiasing can indeed be derived.
One thing that must be understood to recognize how such a scheme will work is that the pattern type output bits from a cell, although still biased if the input bits to the cell are biased, are always less biased than the input. The following diagram illustrates why:
The input bits are mixed with probabilities 1-p and p. The output bits have those probabilities mixed with their reverse; the proportion of the reverse is as 1-p is to p, and so the approach to equal probability is slower when the probability is less equal to begin with, but as long as there is some probability of both values, the growth takes place.
Thus, as part of our overhead, we will be encoding fixed numbers of biased bits, in blocks whose size is a power of two. The encoding of pattern type bits will proceed only to a finite level, and the first bit of the output will be a raw pattern type bit, rather than a final unbiased output bit. The pattern type bit will tell us whether or not an unbiased output bit follows.
When there is no unbiased output bit, it will be necessary to discover what has happened with the compression of next-level bits. In the beginning, there will not be enough next-level bits to further compress, leading to more overhead. Eventually, however, there will be numerous next level bits, and the bits that have been seen will give their exact number.
An example may illustrate the kind of scheme that is possible:
First, let us consider the reduction of 32 input bits to pattern type bits in successive stages.
Input bits: 01 10 11 00 11 01 01 10 11 10 00 10 11 10 01 10 Pattern type: 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 Pattern type: 0 0 1 0 1 1 1 0 Pattern type: 0 1 0 1 Pattern type: 1 1 Pattern type: 0
So our compressed message begins with 0. This indicates that the input to the last stage of the pattern type cascade consisted of two similar bits, and so one next-level bit, rather than one unbiased bit, was produced. Since this scheme won't allow one bit to be compressed, the next bit in the compressed message is the raw next-level bit, 1.
Since 01 decompresses to 11, we now know the next two bits in the message are two unbiased output bits which will give us the four pattern type bits in the next higher row, and they will be 00 (as produced from 0101). So our compressed message is now 0100 representing 0101.
Having the string of pattern type bits 0101, we know we have two unbiased bits, corresponding to the two ones in that string, which do not get further compressed. They will be the next part of our message, and they will be 11, representing the two pairs of bits in the arrangement 10. So, reading the message 010011, we know that the string of eight pattern type bits is of the form ??10??10 so far.
From the string of pattern type bits 0101, we also know we have two next level bits. These next level bits are 01, corresponding to two pairs of bits 00 and 11. Since there are two of them, they will be further compressed, since to allow unambiguous decoding, we compress whenever possible.
By our scheme, 01 when compressed becomes first a pattern type bit of 1, and then a single unbiased bit of 0.
So the string of pattern type bits 00101110 has been compressed to 01001110. So far, of course, no change in length has taken place; this is not surprising, as our string of pattern type bits contains an equal number of ones and zeroes. It should be clear from the foregoing that because we are providing pattern type bits first, decoding is unambiguous: the decoder is assumed to know that the ultimate message consists of exactly 32 bits, as side information the cost of which approaches zero in relative terms as the size of the message approaches infinity.
Now we will apply the known string of pattern type bits at this level to the next higher row in the chart.
The four ones in the original eight pattern type bits indicate we have four unbiased bits to see next. These happen to be 0000, indicating our next higher row has the form ????01??010101??.
The four zeroes in the original eight pattern type bits indicate we also have four next-level bits to contend with. Since there are four of them, they will be compressed.
The four next level bits are 1011.
They give rise to pattern bits 10, which give rise to a pattern bit 1.
So their compression begins with pattern bit 1 followed by unbiased bit 1.
This gives us pattern bits 10, which indicate one unbiased bit of 1, followed by one next-level bit, which, being one bit, cannot be further compressed, and which is 1.
So our next higher row of pattern bits, which was 1100011101010111, has given rise to the compressed bit string of 0100111000001111 so far.
Decoding the compressed bit string gives us the original pattern bits. They tell us that compression of the original 32 biased bits being compressed leads to ten unbiased bits. So the next part of the compressed message will be those ten unbiased bits. They are 0100111101, making the compressed message so far 01001110000011110100111101 which indicates an input bit string of the form 0110??????010110??10??10??100110.
That leaves us with six next-level bits which we have to compress. The six next-level bits to compress are 101101.
Note that six is not a power of two.
Describing our compression process as seen so far as a recursive algorithm, it is:
C(0) -> 0 C(1) -> 1 C(bits) -> C(pattern-type(bits)); unbiased(bits); C(next-level(bits))
Applying that algorithm to the string 101101, we obtain:
Input bits: 10 11 01 Pattern type: 1 0 1 Pattern type: 1
Our problem is that C(bits) is defined based on passing a single cell of the Peres algorithm over the string of bits, and this is only defined for a string composed of an even number of bits. So we need to expand our definition of C(bits) somewhat, for a comprehensive definition:
C(0) -> 0 C(1) -> 1 C(bits;0) -> C(bits);0 C(bits;1) -> C(bits);1 C(bits) -> C(pattern-type(bits)); unbiased(bits); C(next-level(bits))
where "bits" is now defined as a string always containing an even number of bits, but not necessarily a number of bits that is a power of two.
Thus, we now know how to interpret the compressed form of a string of six bits. It will begin with the compressed form of the three pattern type bits they generate, which will be the compressed form of the first two of them, followed by the third bit.
The three pattern bits are 101, and 10 compresses to the pattern type bit 1 followed by the unbiased bit 1. So we begin with 111. This tells us to look for two unbiased bits, and they will be 10. Then we have one next-level bit, and that is 1.
Compression is now ended, and our input string 01101100110101101110001011100110 is now represented by 01001110000011110100111101111101 which is no shorter in this example, as, although the input string did slightly favor ones, it did not do so to a great enough extent to permit any savings.
Decompression is somewhat more involved; the decompression algorithm requires a second parameter, the number of bits to be decompressed, to tell it when to stop reading the initial string of pattern type bits.
However, a closer examination of this algorithm will show that, because of the way in which cells in the Peres unbiasing algorithm operate, it is not possible to increase or decrease the length of a bit string by this method; thus, the algorithm as described here is not one that can compress data. That no increase in the length of a bit string is possible may be slightly more obvious, but that leads directly to the conclusion that no decrease is possible from fundamental principles.
This does not mean, however, that a data compression method cannot be based on Peres unbiasing. One can, and it can even be in many respects similar to the algorithm outlined here.
The difficulty lies in the fact that while the pattern type bits become increasingly less biased, and thus can be handled in the fashion shown here, the next-level bits become increasingly more biased. Thus, in order to use an algorithm similar to the one outlined here to compress a message composed of biased bits, the algorithm must be one modified from the one shown here so that the next-level bits, in which the bias becomes concentrated, are encoded by means of a method that takes advantage of this bias to yield compression, such as run-length encoding.
Incidentally, note that while the bias of the input bits can favor either 0 or 1, if the input bits have any bias, the bias in the pattern type bits will always favor 0, and this fact can be used in determining how to encode next-level bits which concentrate bias from a previous pattern type stage, as opposed to pure next-level bits.