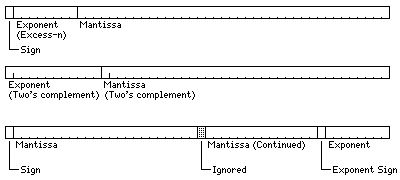
The examples of floating-point numbers shown on the previous page illustrated the most common general type of floating-point format, the one shown in the first line of the diagram below:
The format shown in the first line begins with a single sign bit, which is 0 if the number is positive, and 1 if the number is negative. Next is the exponent. If the exponent is eight bits long, as shown in the diagram, it is in excess-128 notation, so that the smallest exponent value, 00000000, stands for -128, and the largest exponent value, 11111111, stands for 127. Finally, we find the mantissa, which is an unsigned binary fraction.
If the mantissa is normalized, non-negative floating-point numbers can be compared by the same instructions as are used to compare integers.
This format is particularly popular on computers that have hardware support for floating-point numbers. A number of variations on this format are used.
Of course, the length of the exponent field shown in the diagram is only one possibility.
The second line in the diagram illustrates the kind of floating-point format used on computers such as the PDP-8 and the RECOMP II. Here, a floating-point number is simply represented by two signed binary numbers, the first, being the exponent, treated as an integer, and the second, being the mantissa, treated as a fraction, both represented in the ordinary format for signed fixed-point numbers used on the computer.
The third line of the diagram illustrates a kind of format which, with a number of variations, was found on most computers with a 24-bit word length. Computers with a 48-bit word length, on the other hand, typically had hardware floating-point, and used a floating-point format of the type given in the first line.
Why did these computers use such an unusual floating-point format?
Typically, although these computers did not have hardware floating-point support, the way bigger computers with a 32-bit, 36-bit, 48-bit, or 64-bit word length did, they did come standard with hardware integer multiplication, unlike smaller computers with an 18-bit, 16-bit, or 12-bit word length.
In order to support floating-point arithmetic, the format of double-precision fixed-point numbers on most of these computers omitted the first bit of the second word of the number from the number itself, sometimes treating it as a second copy of the sign, so that fixed-point numbers could be treated as having the binary point on the right, making them integers, or on the left, after the sign, making them fractions on the interval [0,1), without having to adjust them by shifting them one place to the left after a multiplication.
A number of variations of each type of floating-point format exist, of course. When a floating-point format consists of a mantissa field followed by an exponent field, with no omitted bit, the choice of whether to consider the floating-point format as belonging to Group II or Group III is arbitrary.
This page, as currently constructed, has placed all the formats with no omitted mantissa bits in Group II. My current thinking on this issue is now favoring moving those formats where the exponent is part of a partial word within a multi-word format (that is, among those formats on this page, that of the Hewlett-Packard 2114/2115/2116, and that of the SDS 920/930/940/9300 and the SCC 600) in with Group III.
A Group I format, as noted, tends to be used on an architecture for which the initial implementations supported floating-point in hardware. A Group III format tends to be used where the word length is too long to use a full word for the exponent, and hardware multiplication features make it useful to align the beginning of the mantissa with the beginning of a word. The Group II format is most popular with machines with small word lengths and limited hardware arithmetic, but it was also used, as in the case of the Maniac II and the Philco 2000, with architectures that started out with hardware floating-point as well.
Also, in some cases, the floating point formats of different sizes for some machines belonged to different groups. When this happened, all the formats for any one architecture were placed within the discussion of one of the groups of formats included. Particularly unsusual formats discussed below include the single precision floating-point format for the PDP-4, 7, 9 and 15, which can be thought of as a rearranged Group II or Group III format, and the double precision floating-point format of the ICL 1900, which applies the principle of making a double-precision float out of two single-precision floats, usually used with hardware Group I formats, to a base floating-point format which belongs to Group III; this appears to be the result of either successive implementations of the architecture evolving from hardware multiply to full hardware floating-point or the availability of hardware floating-point as an option.
Another case where the same machine had floating point formats belonging to different groups is the Harris 800, which added a Group II quad-precision floating-point format to an existing architecture whose single and double precision floating-point formats belonged to Group III: here, the hardware level seems to have remained constant, and what happened was that the larger size of the quad-precision format made it reasonable to use a full word instead of a partial word for the exponent, and once that was done, a Group II format appeared more reasonable than a Group III format.
The Univac 418 single-precision floating-point format belongs to Group I, and its double-precision format to Group II. Hardware floating-point was only introduced to this architecture with the Univac 418-III, and so this combination is not too surprising.
The diagram below shows several examples of floating-point formats of the first type, but they are only a very small sampling of the number of formats of this type that have been used.
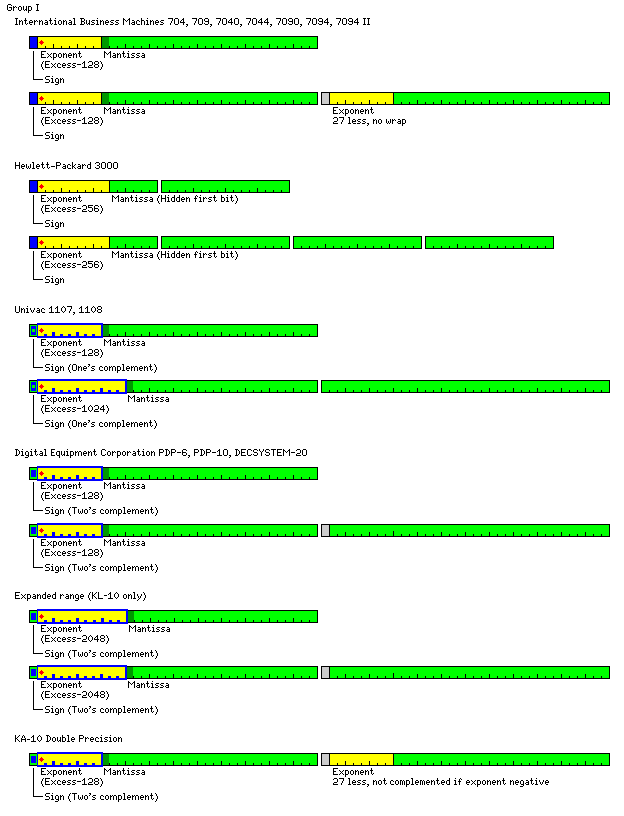
The IBM System/360 computer used an exponent that was seven bits long, in excess-64 notation, that represented a power of 16 instead of a power of two. Thus, a mantissa was normalized when any of the first four bits of the mantissa was not zero. In addition to the computers that were built to be compatible with the System/360 (including the RCA Spectra/70, which was compatible only for user programs), many other computers followed the same floating point format as the System/360, such as the Texas Instruments 990/12, the Data General Nova and Eclipse computers, and the SEL 32.
Another similar computer that I might have expected to use the System/360 format instead originally used a format very similar to that of the PDP-11, except for allocating one more bit to the exponent, and one less bit to the mantissa. During the lifetime of this particular system, a change was made to the IEEE-754 standard format. The system of which I speak is the Hewlett-Packard 3000 series of computers.
The PDP-10 (and its compatible relatives, the PDP-6 and the DECSYSTEM-20) and the Xerox Sigma computers (which, like the System/360, also used a hexadecimal exponent), which both used two's complement notation for integers, performed a two's complement on the combined exponent and mantissa fields of a floating-point number when it was negative. This meant that all normalized floating-point numbers, whether they were positive or negative, could be compared by integer compare instructions, producing correct results.

The Control Data 1604 computer used an exponent field that was 11 bits long; also, it used one's complement notation for integers, and the mantissa (called the coefficient in that computer's manuals) of floating-point numbers was also complemented for negative numbers. Double-precision floating-point numbers, processed in hardware on the later 3400 and 3600, simply added another full 48 bits to the mantissa. This same representation of negative numbers was used on the Control Data 6600, but for a 60-bit floating-point number, again with an 11-bit exponent.
Although it is not shown in the diagram, the Control Data 6600 and its successors such as the 7600 also supported double precision arithmetic. Double precision numbers on the 6600, like Extended Precision on the System/360, and double precision on the IBM 704 and its successors (the 709, 7040, 7044, 7090 and 7094), were composed of two single precision numbers one after another, the second number containing the less significant portion of the mantissa.
Like the PDP-10 and the Sigma computers, the Control Data computers complemented the whole number, including the exponent, if the sign was negative, but unlike them, it was a bitwise one's complement that was used. This means that each value in the exponent field of a positive number strictly corresponded to a complemented value for a negative number, whereas when a floating-point number undergoes a two's complement operation, it at least seems conceptually possible that there could be a carry out of the mantissa field into the exponent field.
This is something I disapproved of, as being messy; however, in practice, since these were formats which did not have a hidden first bit, the one case where you get a carry when you add one, when an all-zero mantissa field is complemented, so it becomes all ones, and then you add one to it to get the two's complement, would not happen unless the floating-point number was zero. Thus, I suspect that the boundary between the mantissa and the exponent doesn't need to have been broken after all, since such machines likely disallowed the floating-point "negative zero".
The diagram depicts the exponent as being in excess-1024 notation; actually, that is not quite accurate. Because of its use of one's complement notation for integers, to use the same type of circuitry for arithmetic on exponents, zero and positive exponents were represented in excess-1024 notation, but negative exponents were represented in excess-1023 notation. Thus, on the Control Data 1604, the exponent value of octal 1777 was not used. On the Control Data 6600, the exponent value of 3777 octal represented an overflow, the exponent value of 0000 octal represented an underflow, and the exponent value of 1777 octal represented an indeterminate quantity. The exponent here is shown as in excess-976 notation, with the binary point located at the beginning of the mantissa field as with the other formats shown here, since it was considered to be in excess-1024 (or excess-1023) notation, but with the binary point at the end of the mantissa, which was considered to be an integer.
Of course, this same floating-point format was used on the compatible successors of the Control Data 1604, such as the Control Data 3600. It was also used on the 24-bit members of that line of computers, such as the Control Data 3300. While I have no definite source for the floating-point format used in software for the Control Data 924, it is very likely to have used the same format, since not only is its instruction format the same as that of the Control Data 1604, but corresponding instructions have the same opcode. Despite the Control Data 3300 and similar machines having indirect addressing added, and fewer index registers, apparently it was possible to write lowest-common-denominator software which could be used by all three types of machine.
The AN/FSQ-31 and 32 computers, built by IBM, had a 48-bit floating-point format which could be represented by the same diagram as that used for the floating-point format of the Control Data 1604, but it lacked the above-described peculiarities of that computer's floating-point format, and simply used excess-1024 notation consistently for the exponent. These computers, with a 48-bit word, used 11 bits for the exponent and 37 bits for the mantissa.
The Cray-1, on the other hand, had a sign bit, 15 bits of excess-16,384 exponent, and 48 bits of mantissa using the more common sign-magnitude format for floating-point numbers.
This computer had one interesting and unique feature. The exponent could be zero, indicating that the mantissa would also consist of all zeroes, to represent zero. If the exponent was not zero, however, only values from 8,192 through 24,575 would be considered valid. Thus, only the inner half of the exponent range was normally used; the high half of the range of positive exponents, and the low half of the range of negative exponents, were treated as overflows and underflows.
It seemed to me that this feature likely had something to do with making it possible to resume a calculation which was halted by an overflow or an underflow; the numbers in the calculation could be rescaled so that everything would be in the proper range, and then the calculation could continue from where it was.
Thinking about it a bit more, though, it seemed as though a step like this wasn't necessary for such a purpose; if the calculation had halted, then an interrupt would have taken place, and if it is known that an overflow, or, instead, an underflow, took place, then it would still be possible to determine unambiguously how to adjust a result which underwent exponent wrap-around.
Since it would be necessary to know the exact point in a calculation at which such a result was produced, if resuming the calculation was intended, the other explanation for this feature - that it allows dealing with out-of-range values without the overhead of an interrupt - did not seem to make sense either, as in that case, one special exponent value to indicate a NaN would serve.
The Burroughs 5500, 6700, and related computers used an exponent which was a power of eight. The internal format of a single-precision floating-point number consisted of one unused bit, followed by the sign of the number, then the sign of the exponent, then a six-bit exponent, then 39-bit mantissa. The bias of the exponent was such that it could be considered to be in excess-32 notation as long as the mantissa was considered to be a binary integer instead of a binary fraction. This allowed integers to also be interpreted as unnormalized floating-point numbers.
A double-precision floating-point number had a somewhat complicated format. The first word had the same format as a single-precision floating-point number; the second word consisted of nine additional exponent bits, followed by 39 additional mantissa bits; in both cases, these were appended to the bits in the first word as being the most significant bits of the number.
The BRLESC computer, with a 68-bit word length, used a base-16 exponent; it remainined within the bounds of convention, as the word included a three-bit tag field, followed by a one-bit sign; then, for a floating-point number, 56 bits of mantissa followed by 8 bits of exponent. Thus, the 68-bit word contained 65 data bits and three tag bits, while the whole 68-bit word was used for an instruction. (In addition, four parity bits accompanying each word were usually mentioned.)
The historic English Electric KDF9 computer used a floating-point format very similar to that of the IBM 7090 computer, except for being adapted to its 48-bit word length. A 24-bit floating-point format was mentioned in the advertising brochure for the machine, but this was not thought of as one of the basic data types of the machine by many of its users. This was because the computer was capable of performing 48-bit and 96-bit floating-point operations, but it had the additional option of doing loads and stores from floating-point numbers in memory in 24-bit format.
The Foxboro FOX-1 computer, with a 24-bit word length, used a floating-point format belonging to Group I; single-precision floating-point numbers occupied only 24 bits, and consisted of the sign followed by a six-bit excess-32 exponent and 17 bits of mantissa.was A negative number was the two's complement of the corresponding positive number, as with the PDP-10 and the Sigma. Double-precision floating-point numbers occupied 48 bits, and consisted of the sign followed by a twelve-bit excess-2,048 exponent and 35 bits of mantissa.
I had wondered why the FOX-1, in particular, had a single-precision floating-point format that was only 24 bits long, as I would have thought that it would have been clear that such a format would not offer enough precision to be useful. This consideration also applies less strongly to the KDF 9 and the Stanford S-1, since they also offered a 96-bit floating-point format, double the length of the much more useful 48-bit floating point format, so in the case of those computers, 48-bit floats could have been single precision, with the 24-bit format reserved for specialized applications.
However, I have been reminded of something which could explain it. Computer manufacturers in the United States would naturally be interested in the U. S. military as a potential customer. At one time (before the adoption of the language Ada) there was a requirement that computers have a FORTRAN compiler available for them to be considered for purchase.
And how to ensure that vendors actually do supply a FORTRAN compiler with their hardware, rather than simply write a compiler for a limited subset of the language, and then call it a FORTRAN compiler? Why, require that the compiler conform to the FORTRAN standard, of course!
And the FORTRAN standard happened to contain one curious requirement. It required that an INTEGER variable (of default precision; alternate precisions of INTEGER variables, as provided by IBM Fortran G, for example, were an extension to the FORTRAN standard) occupy the same amount of storage as a single-precision REAL variable (one "numeric storage unit"), and that a DOUBLE PRECISION variable occupy exactly twice that amoount of storage (two "numeric storage units"). However, the number of "character storage units" in a "numeric storage unit" was not specified, so at least both the IBM 360, with four 8-bit characters per 32-bit "numeric storage unit" and the IBM 7090, with six 6-bit characters per 36-bit "character storage unit" would be compliant - as well as a machine with six 8-bit chracters per 48-bit "numeric storage unit" or a machine with three 8-bit characters per 24-bit "numeric storage unit".
This meant that a 24-bit computer could not simply go with 24-bit integers, and 48-bit and 72-bit floating-point numbers, which would have been the most reasonable for a computer of that word length.
One solution would be to use 48-bit integers, and 48-bit and 96-bit floating-point numbers, as the ICL 1900 did, but that may not have been considered reasonable from a performance viewpoint in some cases.
Also, the CDC 924 computer, which also did not have hardware floating-point support, when it multiplied two 24-bit integers, it produced a conventional 48-bit integer result with no omitted bits. It used one's complement notation for 24-bit integers, but 15-bit values used in the index registers were in two's complement form. It is likely, therefore, that its sofware floating-point format was compatible with the conventional floating-point format used by the CDC 1604.
The Packard-Bell 440 computer was microprogrammable, but its design was optimized for the floating-point format shown here, which belongs to Group I, although it includes an omitted sign bit in the second word. This is also the case for some other Group I formats, whereas this characteristic is the distinction between the Group II formats and the Group III formats.
The Univac 418 computer used a Group I floating-point format for single-precision numbers, but its format for double-precision numbers belonged to Group II. Note how some bits of the first word were ignored because 15 bits was felt to be more than adequate for an exponent field, and that the exponent was complemented for negative numbers only for the single-precision Group I format.
The S-1 computer, built at Stanford University, is noteworthy for having a floating-point format even shorter than that of the Foxboro FOX-1 computer. While 16-bit floating-point formats are used today with graphics cards, floating-point formats shorter than 32 bits were seldom used with general-purpose computers. Note, though, that it used a floating-point format with a hidden first bit, like that of the PDP-11; the extra bit of precision this provided would have been particularly beneficial with this format.

The Control Data 6600 had a word length of 60 bits, and so its normal floating-point format had a precision comparable to that of the double precision floating-point numbers of many other computers.
Despite this, it still offerred support for double-precision floating-point arithmetic. It did so in a fashion similar to the IBM 704 computer, by offering instructions that performed arithmetic operations on single-precision numbers which retained the information necessary to conveniently use those instructions as part of code to perform a double-precision operation.
Unlike the IBM 704, however, it also provided simpler versions of the single-precision operations that did not retain this information.
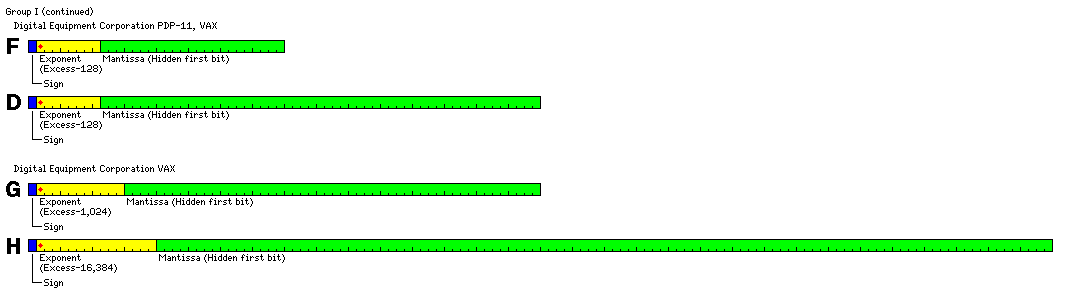
Other computers, such as the PDP-11, and its successor, the VAX, dealt with the wastefulness of having the first bit of the mantissa (almost) always one by omitting that bit from the representation of a number. The number zero was still represented by a zero mantissa combined with the lowest possible exponent value; thus, this exponent value had to be given the additional meaning that the hidden one bit was not present. The diagram above shows only one of the formats used with the PDP-11, although in single precision it was called the F format, and in double precision, the D format. An early sofware format, belonging to Group II, also existed; it involved a 16-bit two's complement exponent followed by a 32-bit two's complement mantissa; unlike H format, it did not have a hidden first bit, and the sign of the mantissa was within the mantissa.
On the VAX and on the Alpha; other formats were used, including the G format, which had an exponent field that was 11 bits in length, used in a 64-bit floating-point number, and which led to the expanded range format for the PDP-10 which is shown above, and the H format, which had an exponent field 15 bits in length, and which was used in a 128-bit floating-point number; these formats are also shown above. Note that the hidden first bit was retained even in the 128-bit format, unlike the case for IEEE-754.
Of course, the Alpha now also supports the standard IEEE-754 floating-point format, which is described here as the "Standard" floating-point format. In its documentation, the 32-bit format is referred to as S format, and the 64-bit format is referred to as T format. In other documentation, the term X format is applied to the new 128-bit format added to IEEE 754. Of the old VAX formats, Alpha chips support arithmetic in F format and G format, and can convert to and from the D format.
The current standard floating-point representation used in today's microcomputers, as specified by the IEEE 754 standard, is based on that of the PDP-11, but in addition also allows gradual underflow as well. This is achieved by making the lowest possible exponent value special in two ways: it indicates no hidden one bit is present, and in addition the value represented by the floating-point number is formed by multiplying the mantissa by the power of two that the next lower exponent value also indicates. It is therefore considerably more complicated than the way in which floating-point numbers were typically represented on older computers.
Of course, the current official floating-point standard, IEEE-754, involves a format that also belongs to Group I:

As it was already depicted on a page in my discussion of an imaginary computer architecture, I had been hesitant to depict it here.
The single and double precision formats both have the suppressed first bit introduced on the PDP-11 and also taken up by the HP 3000. The lengths of the exponent fields match those of the Univac 1107 and its successors.
Essentially, one can trace the lineage of the IEEE 754 floating-point format back to the IBM 704. That floating-point format was continued with the 7090, and both the Univac 1107 mainframe and the DEC PDP-10 computer chose to be largely, but not completely, compatible with it.
The Univac 1107 added a longer exponent part for double-precision numbers, which went directly to the IEEE 754 format.
The PDP-11 computer, with a 16-bit word, was given a floating-point format with the same size of exponent field as the PDP-10 for compatibility. Of course, with a 16-bit word, the lengths of floating-point numbers were now 32 and 64 bits, not 36 and 72 bits. This loss of precision was perhaps what encouraged the designers of PDP-11 floating-point to come up with the hidden first bit, also incorporated into the IEEE 754 standard, and one of its features considered unusual at the time.
In the 80-bit "temporary real" format used in the 8087 coprocessor, the hidden first bit was not used; this is not simply because the extra precision is not needed in a longer format, but also because this format is intended for internal use.
Two new formats have recently been added to the IEEE 754 standard, a 128-bit format and a 256-bit format. These formats also have a hidden first bit, and are now also shown in the diagram above. The exponent length is the same as that for temporary real, but because it also has a hidden first bit, this format offers an additional bit of precision compared to what one would get by extending temporary real to 128 bits.
The Motorola 68000 family of microprocessors used extended precision numbers that occupied 96 bits; however, they consisted of a one-bit sign, fifteen bits of exponent, and then sixteen unused bits, followed by a 64-bit significand in which the first bit was not hidden. So they provided the same precision as an 80-bit temporary real number on an Intel 8087, but had a length that was a multiple of 16 bits for faster storage access.
The IEEE 754 standard does not specify a temporary real or extended precision format, which is why some implementations of the standard use 80 bits, and others use 128 bits. As well, the extended precision format for IEEE 754 floating point numbers (or binary floating-point (BFP) numbers) on IBM mainframe computers, although it has the same 15-bit size for the exponent as shown here, increases the precision of the mantissa by one bit, because it still has a hidden first bit, unlike the temporary real formats used on Intel microprocessors.
Some of the formats of the type given in the second line of the diagram at the top of the page are illustrated below:
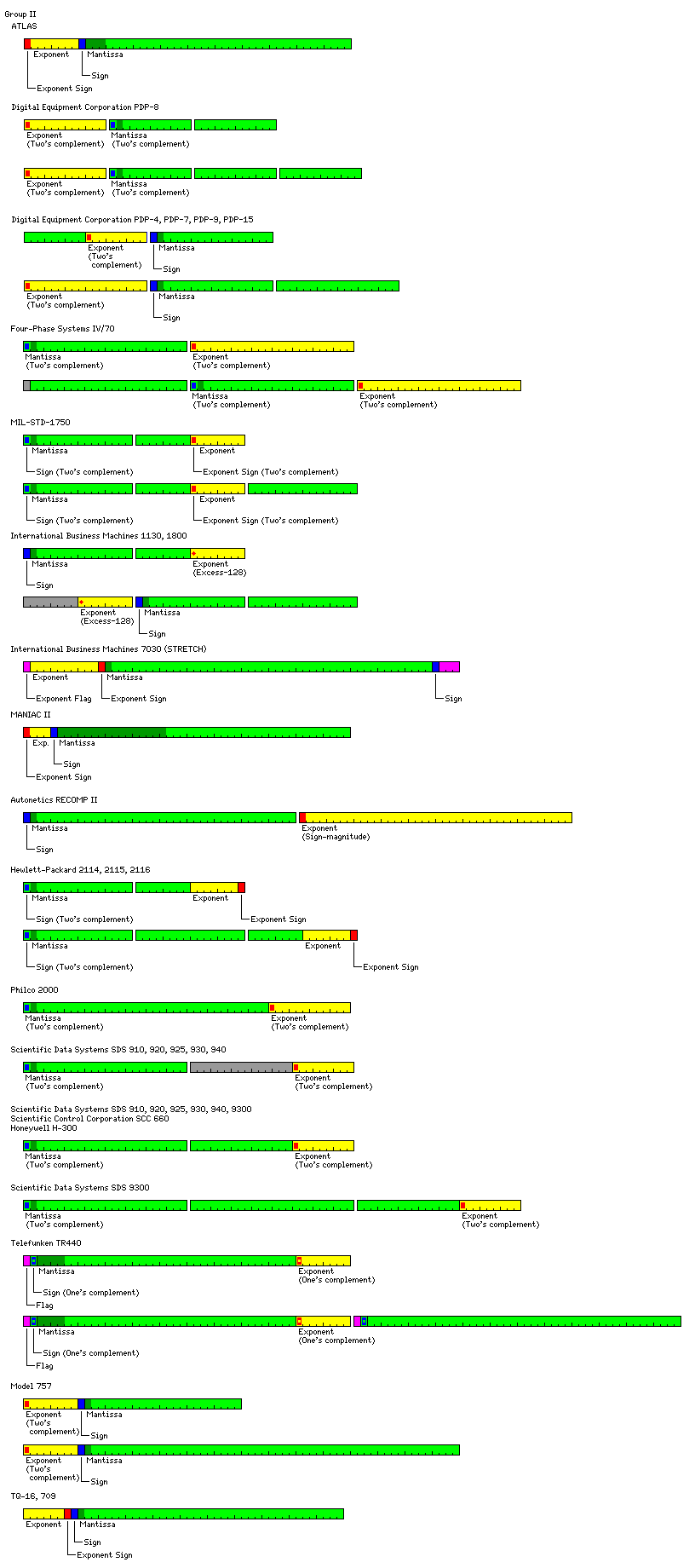
The Manchester ATLAS computer, notable for introducing virtual memory, used an 8-bit sign-magnitude exponent followed by a 40-bit sign-magnitude mantissa. The exponent was a power of eight. A power-of-eight exponent was also used on the Burroughs 5500; thus, a claim I once read that a power-of-eight exponent did not, in practice, lead to the type of problems encountered with the power-of-sixteen exponent on the IBM System/360 could have had practical experience behind it.
The floating-point hardware optionally available for the PDP-8, called the Floating Point Processor-12, as it was originally introduced as an option for the PDP-12 (an updated version of the LINC-8), and a set of floating-point routines for the PDP-8 available as a separate product, both used a single 12-bit word for the exponent, and multiple 12-bit words to represent the mantissa. This format was also supported by a software package, FPS, the Floating-Point System, for the PDP-8.
The original FPP-12 only supported one floating-point precision, involving one word of exponent and two words of mantissa. The FPP-12A also supported double precision, with five words of mantissa. On the other hand, the Floating Point System supported the format with two words of mantissa, but there was also a Four Word Floating Point version of the package that supported a 48-bit format with three words of mantissa, the longer format shown in the diagram above.
Other floating-point representations also were used in software on the PDP-8, however; for example, 8K FORTRAN used a format which began with one bit for the sign of the number, followed by an eight-bit signed exponent, with the first three bits of the mantissa completing the first word; this format belonged to the class illustrated by the first line of the diagram above, and was used in order to provide compatibility with the PDP-10 and/or the IBM 7090. However, 4K FORTRAN for the PDP-8 used the same floating-point format as the Floating Point Processor and the Floating Point Package (also known as the Floating Point System).
The Group I format from 8K FORTRAN was also supported by the "27-bit Floating Point Package".
Double-precision floating-point numbers on the PDP-4, 7, 9 and 15 were represented by one 18-bit word for the exponent, and two 18-bit words containing the mantissa; the format of single-precision floating-point numbers on those machines was more complicated, and therefore of a form which does not fully belong to any of the three groups examined here, but which allowed quick conversion to the double-precision floating-point format by first appending a copy of the first word as the third word, and then performing masking and, in the case of the exponent, sign extension.
The Four-Phase Systems IV/70 computer was marketed as a system for database applications, and thus floating-point capabilities were a secondary consideration. Thus, a full 24-bit word is used for the exponent, In addition, not only were single-precision floating-point numbers required to be aligned on 48-bit boundaries, but the last 48-bits of a double-precision floating-point number, which had the form of a single-precision float, to which a 24-bit word containing an additional 23 mantissa bits were prepended, also had to be so aligned. This meant that an array of double-precision floating-point numbers would have to contain at least one additional word of storage between successive array elements. This unusual state of affairs can be explained, however, by the fact that only single-precision floating-point aritmetic was directly implemented in hardware on the system.
The IBM 1130 computer did not have hardware floating-point, but its FORTRAN compiler used the floating-point formats shown here. The compiler, for Basic Fortran IV, did not support double-precision; instead, when compiling a FORTRAN program, you could simply request extended precision, so that instead of the default two-word format being used, the second, three-word format would be used instead for all the floating-point numbers in the program. While the IBM 1130 was a 16-bit computer, it did have instructions for 32-bit arithmetic, and so, in order to avoid making floating-point operations unreasonably slow for little benefit, eight bits were left unused instead of extending the precision to 39 bits for the three-word format.
In the IBM 7030 or STRETCH computer, an exponent flag bit was followed by a ten bit exponent, the exponent sign, a 48-bit mantissa, the mantissa sign, and three additional flag bits. The exponent flag was used to indicate that an overflow or underflow had occurred; the other flag bits could simply be set by the programmer to label numbers.
The SDS 910, 920, 925, 930, 940, and 9300 computers used two's complement representation for integers. When they performed a fixed-point multiply, the product was a 48-bit fraction; the most significant bit of the second word was not skipped. The SDS 9300 had a hardware floating-point unit, and, thus, its manual described a hardware floating-point format consisting of a 39-bit two's complement mantissa followed by a 9-bit two's complement exponent. Therefore, although the floating-point format did belong to this general class, by virtue of having the exponent at the end rather than the beginning, it did not include a skipped bit in floating-point numbers.
The program logic manual for the FORTRAN IV compiler for the SDS 9300 noted that three words were required to store a double precision number; double precision was performed in software; the actual format used may not be as shown in the diagram, as it could instead be something not quite as tidy and regular in order to facilitate using the single-precision floating-point hardware instructions to speed up double-precision calculations.
In the manuals for the SDS 910, 920, and 930 computers, on the other hand, it was noted that the 48-bit format with all bits used was the double precision format; the single precision format was also 48 bits long, but with the mantissa bits in the second word of the double precision format left unused.
The Scientific Controls Corporation 660 computer also used, as its normal floating-point format, the full 48-bit format shown in this section of the diagram.
This format was also used by the Honeywell 300 computer. This computer, with a 24-bit word length, did not have the same instruction set as either the 24-bit DDP-224, also by Honeywell, or the 48-bit Honeywell 800. This computer was advertised as providing a very favorable combination of price and performance, and was packaged as a small mainframe. It was notable for introducing ferrite cores including lithium, which had better temperature characteristics.
The Scientific Control Corporation 660 computer used two's complement notation for integers, and also produced a 48-bit fraction when it multiplied two 24-bit fixed-point numbers, and its floating-point format also consisted of a 39-bit two's complement mantissa followed by a 9-bit two's complement exponent.
It may also be noted that the MANIAC II computer used a floating-point format where the exponent was a power of 65,536. This reduced the number of shifts required, which was very important on a very early vacuum-tube computer, although the maximum possible loss of precision was rather drastic on a machine with a 48-bit word length. But the machine performed floating-point arithmetic only, and it used only a four-bit field for the exponent and its sign; thus, the intent behind its floating-point format can be considered to be one of using a format that is halfway between conventional floating-point format and integer format, so as to obtain the extended range of the former with the speed of the latter.

The RECOMP (and its similar successors, the RECOMP II and RECOMP III), from the Autonetics division of North American Aviation, a computer which used a head-per-track disk as its main memory (thus behaving much the same as a computer with drum memory) which had a 40-bit word length, simply used one 40-bit word for the exponent, and one 40-bit word for the mantissa. (Incidentally, it used sign-magnitude notation for numbers, not two's complement.) While this was obviously done merely to simplify the design of the computer, an advertisement, shown at right, (appearing in several magazines, including Scientific American, in early 1960) extolled the ability of this computer to handle numbers which, if written down, would girdle the entire globe.
A much better copy of this advertisement is on-line here; the image I am using is from a black-and-white scan of an old magazine in which this advertisement appeared, and I restored the coloring by hand in a paint program, so my image may be imperfect.
This diagram does not show all the formats of this type that were in use; the Paper Tape Software Package for the PDP-11 included a Math Package with floating-point routines that worked on a format consisting of a 16-bit two's complement exponent followed by a 32-bit two's complement mantissa.
Another floating-point format that could be considered as belonging to this class (although I now tend to incline to placing it in Group III) was used with the Hewlett-Packard 2114/5/6 computers. A floating-point number began with a two's complement mantissa, and then ended with seven bits of exponent, followed by the sign of the exponent, neither of which was complemented when the number was negative. Floating-point numbers could occupy either two or three 16-bit words, depending on whether they were single or double precision.
The floating-point format of the Telefunken TR440, a machine with a 48-bit word length, is also shown. Words containing numbers included a flag bit; in memory, this was a second copy of the sign, but internally in arithmetic registers the bit was used for detecting overflows. Both the mantissa and exponent parts of a floating point number were in one's complement format just as integers were on this machine. Like the IBM 360, the exponent was a power of 16. But the mantissa field in single-precision was 38 bits long, so, as in the MANIAC II, the length of the mantissa field was not a multiple of the digit size.
Also shown is the floating-point format of the Model 757 computer, the first vector supercomputer produced in mainland China. (It is possible that the exponent is in one's complement form instead of two's complement form as shown.) In addition to the single precision and double precision forms shown, it also had a 128-bit extended precision floating-point format. The additional 64 bits provided an additional 55 low-order bits of the mantissa; the sign was duplicated, and so was the exponent (as opposed to being offset, as in the double-precision format of the IBM 7090).
Also from the People's Republic of China is shown the floating-point format used in the TQ-16 and Model 709 computers. The exponent and the mantissa are both in sign-magnitude format, but the format is unusual in that the sign of the exponent follows the exponent, so that the two signs are adjacent to each other. Thus, this format could be considered to be one of the few floating-point formats that does not belong to my scheme of Group I, II, and III formats, which otherwise seems to encompass the floating-point formats of most of the computers I am aware of that use floating-point numbers in either hardware or software.
I still put it into the diagram for Group II floating-point formats, since the exponent and the significand were both self-contained, even though I had given some floating-point formats their own diagram. On reflection, since if the exponent and significand are both in sign-magnitude format, in a Group I format the signs of the two parts are adjacent, it seems to me that a possible explanation for this format could be that it was originated by a committee in which some members preferred a Group I format, and others preferred a Group II format, with this format arising as an attempt to obtain the benefits of both kinds of format.
Since the benefit of the Group I format is that it is conceptually an arrangement of the elements of a floating-point number that puts the most significant parts first - and, indeed, if the significand is inverted for a negative number, one can even use integer comparison instructions on floating-point numbers - and the benefit of the Group II format is that one has two elements both of which can be processed as normal integers, it seems to me, however, that this format did not succeed in obtaining the benefits of either.
But special circumstances (for example, a particular type of shift circuitry) could have meant this format was easy to convert to either a Group I or Group II format. Specifically: a circular right shift of one position for the first seven bits would change it to a Group II format, and then if one subsequently subjects the Group II version of the number to a circular right shift of one position for the first eight bits, that would change it to a Group I format!
If the architecture to which it belonged was intended to be implemented on a range of compatible machines with different performance levels, like that of the IBM System/360, then one could indeed imagine conversion to a Group II format internally for the lower-performance machines which use integer arithmetic to carry out floating-point calculations. But converting to a Group I format (or even not using a Group II format in the first place) does not really make sense for the higher-performance machines, since a Group I format only has benefits if it's the visible format of the architecture.
So this attempt at an explanation does not seem to work out either.
Another Group II floating-point format which I have not attempted to include in the diagram is that of the LEO III computer.
This computer had a 42-bit word (with an additional four bits per word for security features and two parity bits), and the 42 data bits included two sign bits. If the word contained a single longer integer that filled the word, one of the sign bits was ignored.
Floating-point numbers occupied three half words each. A floating-point number consisted of a 37-bit mantissa which occupied one full word, and a 21-bit exponent which occupied a half word.
To make floating-point operations more efficient, the mantissa was always stored as an aligned full word. Thus, a pair of floating-point numbers was stored in memory as:
As well, the addressing of halfwords was little-endian, and so in a diagram showing this in successive words of the computer, it would appear that the exponent of the second number, being on the left of the middle word, came first, thus making the two numbers intertwined.
The floating-point formats of many 24-bit computers followed the model shown in the third line of the diagram at the top of the page, but they varied in minor ways from it, and are illustrated below.
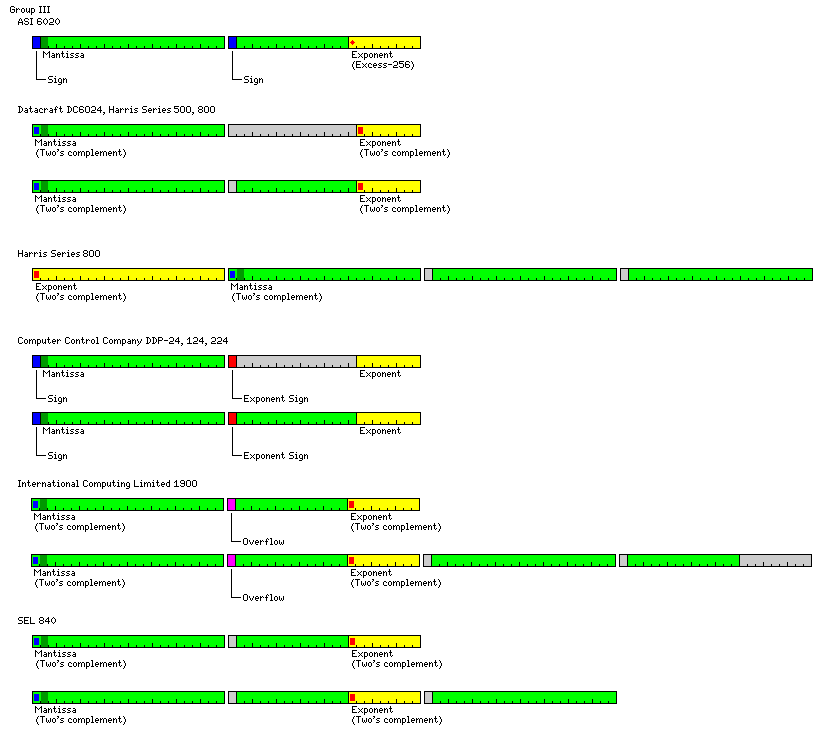
The ASI 6020 computer used a 39-bit mantissa in sign-magnitude format, followed by a nine-bit exponent in excess-256 notation, a rare instance of excess-n format being used in a Group III representation of floating-point numbers.
The Datacraft 6024 computer, and its successors from Harris, used two's complement form to represent integers. The exponent field, including sign, was eight bits long. The basic format shown above was used for double-precision floating-point; in single-precision floating point, numbers still occupied two 24-bit words in memory, but the portion of the mantissa in the second word was not used.
The Harris 800 computer added a quad-precision floating-point format that used a full 24-bit word for the exponent. In this format, the exponent came first instead of last, so it belongs to Group II. The sign bits of the second and third words of the mantissa were unused, but this is even found in some of the double-precision formats in Group I.
The DDP-24 computer, from 3C and then Honeywell, used sign-magnitude representation for integers, and a multiply instruction ensured both words of the product contained the same sign. It also left the mantissa portion of the second word unused for single-precision numbers. The eight least significant bits of the second word contained the value of the exponent; the sign of the exponent was contained in the sign bit of the second word, instead of that bit being unused.
The ICL 1900 computer used two's complement notation for integers. In double-length fixed-point numbers, the first bit of the second word was always zero. The exponent field of a floating-point number consisted of nine bits in excess-256 notation; the first bit of the second word was a flag which, if one, indicated that a floating-point overflow had taken place. Single-precision numbers were 48 bits long. A double-precision number was 96 bits long; in the second half of the number, which contained the least significant 35 bits of the mantissa, the first bit of each word, and the area corresponding to the exponent field in the first half, were ignored.
The SEL 820 computer, which I believe to be the last of the major members of the "classic" group of 24-bit computers to be described on these pages (here, I am thinking primarily of the Datacraft DC 6024, the Computer Controls Corporation DDP 224, the ASI 6020, the SDS 920 and the SDS 9300, as well as the other computers compatible with these as belonging to this group) has its floating-point format illustrated here as well. Despite the fact that the exponent is at the end of the number and not the beginning, the double-precision format simply appends a word of mantissa to an unaltered single-precision floating-point number.
Here are two floating-point formats

from computers in the former Soviet Union; that of the M-20 is a Group I format, and that of the BESM-6 is a Group II format.
In the discussion above, I refer to the two major fields in a floating-point number as the "exponent" and the "mantissa". It should be noted that these designations are not without controversy.
The base-10 or common logarithms of numbers, when used for facilitating arithmetic calculations, are divided into an integer portion, called the characteristic, and a fractional part, called the mantissa. Furthermore, when dealing with numbers less than one, whose logarithms are negative, instead of noting the logarithm as a conventional negative number, the integer part is decremented by one (increased by one in magnitude) and noted with a bar over it, instead of a negative sign in front, to indicate that the property of being negative applies to it only, so that the fractional part can be left positive. This further facilitates arithmetic with logarithms, and is illustrated below:
Number Base-10 Logarithm Conventional Common Logarithm
Characteristic Mantissa
1250 3.096910013 3.096910013
1.25 0.096910013 0.096910013
_
0.00125 -2.903089987 3.096910013
When numbers are written in scientific notation,
3
1.25 * 10
0
1.25 * 10
-3
1.25 * 10
clearly the exponent to which 10 is raised conveys the same information as the characteristic of the logarithm, and the number by which the power of 10 is multiplied conveys the same information as the mantissa of the logarithm.
The exponent and the characteristic are the same integer, while the mantissa is the logarithm of the number by which the power of 10 is multiplied, rather than that number itself.
Despite this distinction, the corresponding two fields of a floating-point number were referred to as the "characteristic" and the "mantissa" in the documentation for the Univac Scientific 1103A computer, and these terms continued to be used with the successor 36-bit architecture used in the Univac 1107 computer and with other Univac computers, like the Univac 418 and 494 real-time systems.
IBM, on the other hand, was even at an early date dissatisfied with the apparent misuse of the word mantissa, and referred to the two fields of a floating-point number as the "characteristic" and the "fraction" across architectures ranging from the IBM 704 to the System/360. These terms were also used by Xerox in association with its Sigma series of computers, designed to closely resemble the System/360 in some aspects without being compatible. They were also used with the English Electric KDF9 computer, an unrelated machine, and the Foxboro FOX-1.
The SDS 9300 computer, made by the same company that later produced the Sigma computers and was then acquired by Xerox, came with documentation that referred to those fields as the "exponent" and "fraction". The same designations were used in the documentation for the Digital Equipment Corporation PDP-6 and its successors, the PDP-10 and the DECsystem-20, as well as the VAX, the Interdata-8/16 and 7/32 computers, the RC4000, and the Scientific Controls Corporation 660 computer. IBM also slipped, and used these designations in its manual for the STRETCH.
The documentation for other DEC computers, such as the PDP-8, PDP-11, and PDP-15, used the terms "exponent" and "mantissa". These terms were also used in documentation for the Atlas, the Burroughs B5500, the Data General Eclipse MV/4000, the Datacraft DC6024 and its successors from Harris, the DDP 24, the General Electric 235, the Hewlett-Packard 2116, the Honeywell series 6000, the Philco 212, the SEL 840A, among other computers, and with Floating Point Systems' add-on array processing unit for minicomputers as well. Even the RCA Spectra 70 computer, largely compatible with the IBM System/360, used these terms in its documentation in preference to IBM's.
When Seymour Cray left Univac to form Control Data, this new company used the terms "exponent" and "coefficient" in the documentation for the Control Data 1604 and the 6600, and these same terms were used in the manual for the Cray I.
As for the ICL 1900 computer, its documentation used the terms "exponent" and "argument".
And, in the description of the IEEE 754 standard for floating-point numbers, which was first implemented in the 8087 math coprocessor for the Intel 8086 and 8088 microprocessors, the fields were referred to as the "exponent" and "significand". I had wondered if the term "significand" had been coined during the standardization process, by analogy with the term "multiplicand", but I have since discovered that it was in existence long before that had begun.. In the book Floating-Point Computation, its author, Pat. H. Sterbenz, cites G. E. Forsythe and C. B. Moler as having used this term in 1967 in Computer Solution of Linear Algebraic Systems.
In this connection, it may be noted that the manual for the RECOMP II computer tried very hard to please everyone, by noting that in its two-word floating-point format, "One word contains the mantissa (fraction) and the other word contains the characteristic (exponent)."
To summarize the information listed in the preceding few paragraphs, concerning the designations for the fields of a floating-point number as used by different computer manufacturers, here is a convenient table:
| characteristic | mantissa | Univac (Univac Scientific 1103A, Univac 1107, Univac 418, Univac 494) |
| characteristic | fraction | IBM (IBM 704, IBM 7090, IBM System/360); XDS Sigma; English Electric KDF9; Foxboro FOX-1 |
| exponent | fraction | SDS 9300; DEC PDP-6, PDP-10; IBM 7030 (STRETCH); Interdata-8/16, 7/32; Regencentralen RC4000; SCC 660 |
| exponent | mantissa | DEC (PDP-8, PDP-15, PDP-11); Atlas; Burroughs B5500; Data General Eclipse MV/4000; Datacraft DC6024; DDP 24; GE 235; HP 2116; Honeywell 6000; Philco 212; SEL 840A; RCA Specra 70; FPS AP-120B |
| exponent | coefficient | Control Data (CDC 1604, CDC 6600), Cray I |
| exponent | argument | ICL 1900 |
| exponent | significand | IEEE 754 standard |
The terms "exponent" and "mantissa" appear to be the ones most commonly found in general use for these two portions of a floating-point number. I've seen it used, for example, in textbooks for users of the IBM System/360 computer, despite the conflict with the terms actually used in manufacturer documentation. I have used them here, as it is my opinion that the primary purpose of language is to convey information easily and rapidly, and using less common if more correct terms would hinder this.
This is despite the fact that one would never use the term mantissa for the corresponding portion of a number written in scientific notation. It may well be properly called the significand; since a numerical term multiplying a variable in algebra, such as the 3 in 3x+5, is called a coefficient, and an input to a formula is called an argument, it is easy to see how these terms could have been used as well.
In the early days of using floating-point arithmetic with computers, it was natural to take terms that were familiar and which quickly indicated what they referred to. The two fields of a floating-point number contained the same information as the characteristic and the mantissa of the logarithm of the number it represented, and so those names were used initially. Since the word "characteristic" is commonly used with many other meanings, it gradually gave way to the term "exponent", which was more immediately understandable.
There was, on the other hand, no readily available substitute for "mantissa"; while "coefficient" and "fraction" were also used, they did not indicate the function of this part of a floating-point number as clearly. Thus, despite the fact that the term "mantissa" could be said to be simply incorrect, since it is the number itself, normalized to a small range of magnitudes, rather than a part of the number's logarithm, it continued to be used. At least, the term "significand" also clearly indicates the function of this part of a floating-point number.
Still, "exponent" is less specific than "characteristic" in much the same way as "coefficient" is less specific than "mantissa". But, in the former case, "characteristic" has, as noted, other commonly-used meanings in English, while "mantissa" is only used with one other meaning, and that one closely related to the intended one. Thus, the evolution of this terminology is an illustration of how languages develop, by people settling on those terms that are the easiest for them to remember, and which cause them the least confusion.
To indicate the depth of feeling that this issue has aroused, in Seminumerical Algorithms, Volume 2 of The Art of Computer Programming, Donald W. Knuth correctly notes that the use of the term "mantissa" for this field of a floating-point number constitutes an "abuse of terminology", and goes on to note that "mantissa" has the meaning of "a worthless addition" in English.
In the case of the ICL 1900, one wonders if perhaps during the design of its architecture, or the preparation of its documentation (or perhaps those of its Canadian predecessor, the Ferranti-Packard 6000) someone might have decided to choose the term "argument" for this field because it seems to be good at starting one.
Of course, floating-point does not strictly correspond to scientific notation. Even when decimal rather than binary arithmetic is involved, the form
+ - 02 12500000
would refer to
-2
0.125 * 10
which, of course, is equal to
-3
1.25 * 10
and, thus, with the radix point preceding the leading edge of the field, it does contain a fraction, explaining IBM's chosen terminology.
I had been interested in finding out if the components of a number expressed in scientific notation had ever been given conventional names, and had thought that perhaps this would have been done around the time of its origin. Another place to look would be in textbooks of arithmetic of a traditional bent which dealt with scientific notation.
Archimedes, in The Sand Reckoner, illustrated large numbers by means of exponentiation, and René Descartes is responsible for our modern notation for exponentiation, and thus I have come across web sites crediting each of them with its invention. However, the use of scientific notation in its modern form appears to date from the late 19th century; this page gives as its earliest example of the use of modern scientific notation one from a paper by Johann Jakob Balmer in 1885, and on the same web site, this page notes a use of the name "scientific notation" from a book published in 1921, which beats the Oxford English Dictionary, which had cited another dictionary as its first example of the use of the phrase.
Having failed, however, to find a traditional name for this portion of a number in scientific notation within the mists of time, it can still be noted that that there are other possibilities, as yet unused, for names for the part of a floating-point number which is vulgarly called the mantissa.
The other part, usually called the exponent, really does correspond exactly to the characteristic. So, this part does at least correspond to the mantissa; it is the antilogarithm of the mantissa. As it happens, old tables of the logarithms of sines, cosines, and tangents were called tables of logarithmic sines, cosines, and tangents, so I suppose that one could shorten the name, and call it the antilogarithmic mantissa of a floating-point number. Of course, if it is a special kind of mantissa, that justifies using the common term mantissa after all.
Since the other part is usually called the exponent, which applies when raising anything to a power, rather than more specifically the characteristic, another possibility is to use a nonspecific term for it. The existing term "coefficient" already answers fairly well to that, but another alternative is factor; if the original meaning of mantissa is "a small addition", perhaps this comes as close as anything to a term meaning "a small multiplication".
The term significand is, I must admit, a particularly felicitous coinage, even if it is of recent origin. Just as a multiplicand is that which gets multiplied by the multiplier, the significand is that which derives its significance from the exponent part of the floating-point number. Another way of expressing this might be to call this part of a floating-point number the unscaled number: the number before it is given a scale by the scale factor of the radix to the power of the exponent.
Since this field contains the significant digits of the floating-point number, perhaps we could get even simpler, and just call it the digits field!
Of course, where there is no good word in English for an object, the English language has often had recourse to absconding with a word from some foreign language; as perhaps in some distant land, an obvious and natural name for this has rescued the people there from the perplexity that so besets us.
However, as one final argument for retaining the traditional term "mantissa", it might be noted that while mathematicians working with calculus and related disciplines will continue using the logarithm function for a long time to come, generally the logarithms they will be using will be natural logarithms; that is, logarithms to the base e (2.71828...); and, even in those cases when they use logarithms to integer bases, it will not usually be for the purpose of simplifying the task of performing a multiplication by hand.
Thus, for such purposes, a logarithm will simply be a number, which may be positive or negative, and with an integer part and a fractional part. It is only when using log tables as tools in performing multiplication that it is useful to subtract one from the integer part of a negative logarithm so that the fractional part can always be positive - and it is the fractional part of a logarithm, so modified, that is called the mantissa.
In decimal floating point, 3 * 10-3 might become + -2 3000000, but it isn't going to become + -2 3333333 - that is, for numbers less than one in magnitude, the reciprocal of the number isn't going to be what is represented. This is what floating-point numbers have in common with logarithms in the computational characteristic and mantissa representation.
Because performing multiplication by the aid of logarithms is falling into disuse, and because the term mantissa belongs not to mathematics in the sense of analysis or algebra, but to practical arithmetic, its meaning in connection with floating-point numbers is not, in fact, a threat to the integrity of the language of mathematics.
Note also that the three lines in the first diagram which illustrated the three possible general types of format, as well as the illustrations of floating-point formats in the other diagrams, assume that the component parts of the floating-point number, whether they are 24-bit words or 8-bit bytes, are lined up so as to be in the normal left to right direction from most significant to least significant for representing integers. Thus, on a little-endian machine, the component of the number on the left would be at a location with a higher address instead of a lower one. Note, however, that on at least some machines, while integers were represented in little-endian form, floating-point numbers were represented in big-endian form.
On the PDP-11, a particularly unfortunate variation of this took place. As it was the first computer to attempt to achieve the consistent use of a little-endian representation for data (previous computers were always big-endian when packing characters into words, but sometimes were little-endian when using two words to represent a long integer) I had thought that the likeliest cause of this was a failure of communication concerning the design of the PDP-11 with the engineers designing the FP-11, the hardware floating-point unit for the PDP-11 that first embodied that format. However, a memo clearly showing that the word containing the exponent and the most significant part of the mantissa would be at the lowest address in that format was in fact discussed at the highest levels within DEC, so explaining this as an accident is not possible. It may instead have been that putting the first part of the number in the lowest address would simplify software floating-point, and the fact that there was a clash between that and the ordering of bytes within a word may simply have been thought of as completely irrelevant.
The PDP-11 had a 16-bit word, but could also address and manipulate 8-bit bytes directly. As with many other computers, such as the Honeywell 316, a 32-bit integer was stored with its least significant 16-bit word first, in the lower memory address, so that addition could begin while the more significant words of the operands were being fetched. However, unlike other computers in existence at the time, for consistency, the PDP-11 was designed so that the least significant 8 bits of a 16-bit word had the lower byte address, and the more significant 8 bits of a 16-bit word had the higher byte address.
Because the FP-11 was designed as though the PDP-11 were a big-endian computer instead of a little-endian computer, it placed the most significant 16 bits of the values on which it acted in the 16-bit word at the lowest memory address, the next less significant 16 bits in the 16-bit word at the next higher memory address, and so on.
In addition to floating-point numbers, this included 32-bit integers as well, but as the PDP-11 already posessed instructions to assist in handling 32-bit integers in little-endian format, this flaw was corrected in subsequent extensions to the PDP-11 architecture. The floating-point format, however, remained unaltered.
The byte addressing within a word was a property of the base PDP-11 architecture, and was not altered by the design of the FP-11 as though it were for a big-endian machine. The most significant bit within a 16-bit word inside the FP-11 was still transmitted to the most significant bit of a 16-bit word inside the PDP-11. Hence, in the illustrations of the floating-point format for the PDP-11 shown above, the successive bytes in a floating-point number have addresses in the order:
1 0 3 2 5 4 7 6
instead of
7 6 5 4 3 2 1 0
as is the case on a consistently little-endian machine, as it had been intended to make the PDP-11, or
0 1 2 3 4 5 6 7
as they would be on a consistently big-endian machine, like the IBM System/360 or many other computers.
This aspect of the PDP-11 floating-point format was preserved on the VAX computer, because it included a PDP-11 compatibility mode; this was true not only for the F and D formats, but also for the new G and H formats, as its documentation noted. On the other hand, IEEE 754 floating-point numbers appear to be stored in consistent little-endian order, although the document in which I saw that may have been referring only to Itanium systems and not Alpha systems.