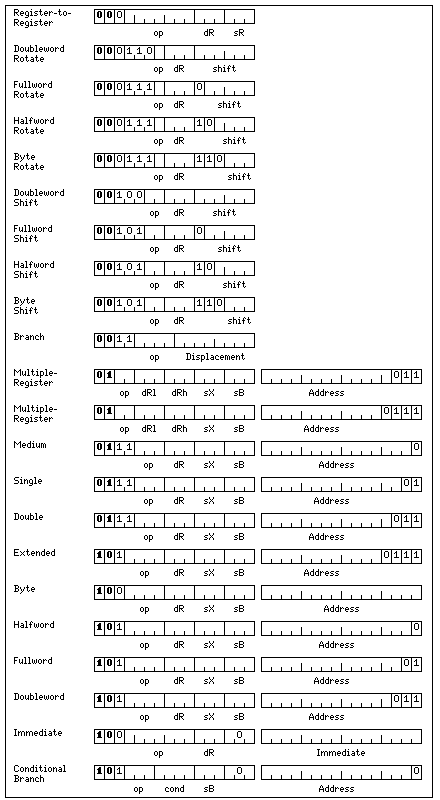
The design of the architecture described in this section was motivated by a desire to provide CISC, RISC, and DSP modes of operation which were as similar as possible.
The different requirements of each mode, however, meant that some of the modes had to go to a more elaborate format for memory-reference operations, where only aligned accesses could be specified, to conserve opcode space. This, and similar cases, led to more differences than the basic differences, seen as required from the outset, such as providing short register-to-register instructions in CISC mode that could be packed two to a 32-bit word.
Thus, since in DSP mode, each 32-bit instruction reserved its first bit as a block mark bit, as a way to improve the efficiency of decoding instructions in CISC mode, by permitting parallel decoding despite variable-size instructions, it was thought to use the first bit of every 32 bits as a warning bit, indicating that the 32 bits in the corresponding position of the next block was the first half of a 64-bit instruction.
One of the consequences of that, however, is that since the first bit of every 32 bits must be reserved, that includes the first bit of the second half of a 32-bit instruction.
So, if it were desired to have 64-bit instructions that contained a 32-bit immediate, the bits of that immediate value could not be contiguous.
Initially, I considered schemes that would fit within the warning bit framework already established.
As two consecutive warning bits could not be set, since the second word of a 64-bit instruction could not also be the first word of another 64-bit instruction, this special combination might signal a block consisting entirely of 64-bit instructions, without any warning bits, followed by a block consisting entirely of 32-bit instructions, in which warning bits were present normally.
Having a block consisting entirely of 64-bit instructions would not cause an excessive inflexibility in the choice of possible instructions, thanks to the Dual Simple format of 64-bit instruction, which allows most major types of 32-bit instruction to be placed in a 64-bit instruction.
This would mean, however, that no location in the block of 64-bit instructions could be a branch target. The instructions in the next block, of 32-bit instructions, could be branch targets, since a branch target is assumed to be a 32-bit instruction, followed only by 32-bit instructions, and the preceding block is not fetched to check the warning bits it contains.
This would make it feasible to have instructions with longer immediates that remained unbroken and in their normal positions. I had even further elaborated the scheme, as follows:
Given that 64-bit instructions cannot cross block boundaries, the last warning bit in a block can never be set. If that bit, instead, were used to indicate a block entirely of 64-bit instructions without warning bits, then the other seven bits could still be used normally as warning bits, so that the next block after could, if necessary, contain 64-bit instructions.
In that case, the other means of indicating a block of 64-bit instruction, setting the first two warning bits, instead of being discarded as obsolete, could serve a special purpose: two other warning bits could be used to indicate that pairs of 64-bit instructions were combined into a 128-bit instruction, to allow 64-bit immediates.
And then if the first two warning bits and the last warning bit were all set, this would indicate two consecutive blocks of 64-bit instructions! With five warning bits left, another pair of warning bits would be available, so that both of them could contain 128-bit instructions.
Presumably, though, the 128-bit instructions would operate like the Dual Simple 64-bit instructions; in this case, a bit at the start of the 128-bit block would indicate whether it was to be considered as a 32-bit instruction followed by a 96-bit instruction, or a 96-bit instruction followed by a 32-bit instruction.
At this point, I realized that the scheme I had come up with was much too complicated to be useful.
The problem was not that decoding instructions would be too complex and difficult; the number of gates required would have been insignificant, and, indeed, much more complex schemes of instruction arrangement have been used in real life.
Instead, the fact that I take advantage of having more opcode bits available in the second half of a sub-block, because I no longer need prefix bits there, in the register-to-register instructions, in the Dual Simple instructions, and now elsewhere, leads to restrictions on instruction placement that would lead to difficulties for the compiler designer. This is exacerbated by the fact that this is the CISC mode, not the RISC mode, and thus only a small number of registers is available, so there would be little flexibility to change the ordering of instructions in response to such restrictions.
Given that the goal was to avoid a need to decode instructions in a serial fashion, as is normally required by variable-length instructions, I next noted another strategy, in addition to the warning bits, which I was already using that satisfied that condition.
Using the opcode field values, it was possible to specify that a 32-bit instruction actually contained two register-to-register instructions without disturbing the decoding of anything that followed.
And the Dual Simple instruction format used that principle again, to allow a 64-bit instruction to actually contain two 32-bit instructions; again, this did not disturb how anything following would be decoded.
Why not go up one more level, and have a 256-bit block initially contain two 128-bit instructions, each of which could then indicate if it were composed of two 64-bit instructions, with the 64-bit instructions, if any, in turn being able to indicate if they were composed of two 32-bit instructions?
And so the prefix coding might be:
110 - 128-bit instruction (32 bits, 96 bits) 111 - 128-bit instruction (96 bits, 32 bits) 10 - 64-bit instruction 0 - 32-bit instruction
In the second half of the 128-bit instruction, if the first half was either a 64-bit instruction or two 32-bit instructions, only 1, rather than 10, would be required to indicate a 64-bit instruction.
In either the first or second half of a 128-bit instruction, in the first half of a 64-bit instruction, 0 would be required to indicate a 32-bit instruction; in the second half of a 64-bit instruction the first half of which was a 32-bit instruction, no prefix would be required.
This scheme certainly had its interest; a fractal structure is, at least, mathematically elegant.
But in some cases, so many prefix bits would be required that instruction formats would be unduly constrained, and the unequal number of prefix bits for an instruction of a given length, depending on where it is located, again made this format unattractively complicated.
And thus I came to the conclusion that it would be preferable to return to a scheme which I had considered before, for the Concertina architecture.
Simply use the first 16 bits of every 256-bit block of instructions to contain a bit, corresponding to each 16-bit area in the block, which is 1 if that 16-bit area is the start of an instruction.
As instructions would not be allowed to cross block boundaries, the first two bits of those 16 bits can be ignored; they might always be set to 01, since the 16-bit area itself is not part of an instruction, and the 16-bit area following, being the first one for instructions in the block, must always begin an instruction.
As, now, length indication is completely removed from the instructions themselves, although 16 bits of every block is lost, the opcode space for the instructions is increased.
As well, since the granularity is now in units of 16 bits instead of 32 bits, instructions with 32-bit immediates can be 48 bits long, and instructions with 64-bit immediates can be 80 bits long, another potential savings of space that would slightly make up for the loss.
Or perhaps the best thing to do would be simply to have a simple prefix coding for each length of instruction, just as was done on the IBM System/360, and as continues to this day on their latest 64-bit machines in the System z family.
The prefix coding I ended up with is:
00 16 bits 01 32 bits 10 32 bits 1100 48 bits (16 bits + 32 bit immediate) 1101 64 bits 1110 96 bits (16 bits + 64 bit immediate) 1111 144 bits (16 bits + 128 bit immediate)
Ordinarily, I would not have copied the System/360 in having both 01 and 10 indicate 32 bit instructions; however, it seemed better to have the lengths in order if possible, and the break was a major enough one in the way instructions were decoded for that not to be too unreasonable.
It was difficult, but I managed with some difficulty to meet demanding requirements of compactness for the instruction coding.
I insisted that only 16 bits would be taken for basic register-to-register opcodes. This required that 96 opcodes, a seven-bit opcode field where the first two bits could be any value except 11. That, of course, was simple enough in itself.
In addition, basic shift and rotate instructions for the different possible lengths of integer operands were to fit in the available 16-bit space.
As well, I wanted, as were provided on several minicomputer architectures, 16-bit conditional branch instructions with an 8-bit signed displacement.
It turned out that in addition to overlapping the opcodes for shift instructions on different length operands based on the length of the item shifted, I also had to break out the rotate instructions to make use of the fact that I had three pairs of instructions; rotate right and left, logical shift right and left, and arithmetic shift right and left - so that I only used the space taken by three pairs instead of four pairs.
There is still some available unused space for 16-bit instructions not yet used; the types of instructions I was concentrating on packing in required too many usable bits to make use of the device of disallowing basic register-to-register instructions where both registers are the same, which I have used in many other places. So I should be able to fit at least a limited number of single-operand instructions in 16 bits as well.
The 32-bit instructions also posed a challenge. To provide sixteen opcodes for memory-reference instructions on Extended precision floats, to accomodate unnormalized operations, which are applicable as that format does not have a hidden first bit, I had to place its instruction code where one for 128-bit integers would belong.
The major challenge, which we have already seen, is that in order to fit the multiple-register instructions in 32 bits, they need to be alloted nearly half of the available opcode space for instructions of that length.
For instructions 48 bits in length and above, I assume at the moment that the length of the instructions will prevent any serious issues of opcode space from being present in their case.
Having achieved the high level of compression I sought for CISC, though, is now not an unalloyed delight, because I have become more aware of the advantages of RISC that have become more important in contemporary designs.
So, I have used the CISC instruction encoding above as the basis for moving another step forwards:
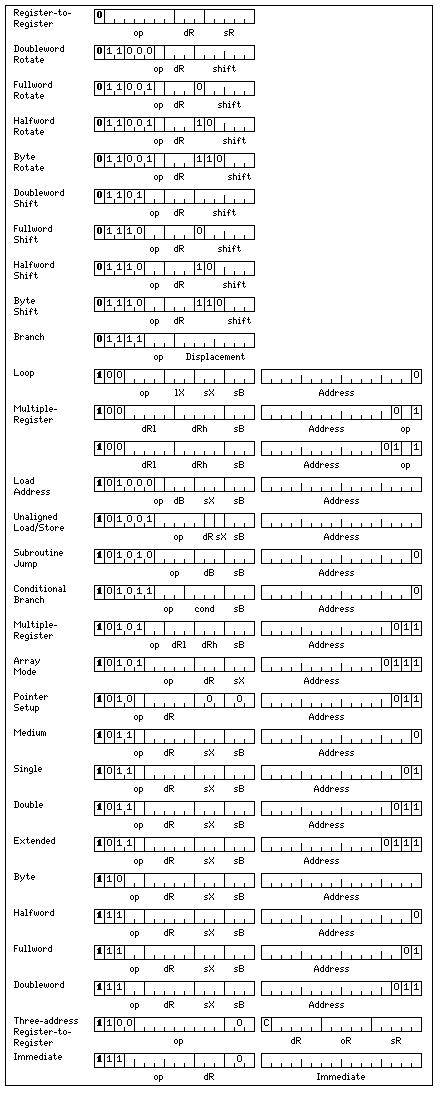
I give up all the instructions with lengths greater than 32 bits. As well, while I retain an 8-bit displacement, now 16-bit conditional branch instructions are restricted to the eight most common forms, as their opcodes shrink to three bits from four.
As with CISC, instructions are variable length, they may be 16 bits or 32 bits long, so the compactness of CISC is retained.
But memory-reference instructions are now restricted to loads and stores.
There are eight address/base registers. But there are 32 integer registers and 32 floating-point registers.
All 32 registers can be the subject of a load, so as with a RISC architecture, loads can be placed ahead of where the data will be used to help deal with the relative slowness of external memory.
The first eight registers of each group of 32, however, are privileged. In many instructions, like the shift instructions, they're the only ones that can be used. Only integer registers 1 through 7 may be index registers. And in a 16-bit register-to-register instruction (which now does not set the condition codes), only the first eight registers can be used as destination registers, although all 32 can be used as source registers.
In order for the load and store multiple instructions to properly handle 32 registers, at first I thought it necessary to limit those instructions to using base registers 4 through 7. But I finally recognized that an expedient was available to avoid this limitation: in the group of opcodes in which these instructions were present, which operated either on the entire contents of the integer registers, and thus aligned on a unit of 64 bits, or the entire contents of the floating-point registers, aligned on a unit of 128 bits, the only other instructions present, distinguished by their alignment, were the instructions used for looping, which pointed to branch targets, having an alignment of 16 bits. Thus, no instructions in this group had an alignment of 32 bits.
Thus, initially, I resolved to produce one extra bit in the 32-bit multiple-register instructions by giving their addresses the suffixes associated with an alignment unit half that which was actually applicable, so that the address could be shifted in these instructions one bit to the right, freeing up the first bit for the opcode bit which indicated that a load or a store was being performed.
Upon further reflection, however, I realized that I did not need to move the address over, but could instead use what was effectively an unused bit in the length encoding directly.
As well, instructions using base register 0 as a base register have been added. The unindexed instructions of this form are the Store Pointer instructions, used to modify the table of pointers to arrays to which base register 0 is intended to point. The indexed instructions are the Array Mode instructions, and they are allocated 32 opcodes, to allow loads and stores for each of eight data types, and are limited to registers 0 through 7, whether integer or floating-point, as their destination registers. The field usually used for the base register is used for the index register of these instructions, which, by making three additional opcode bits available, allows more flexibility in these instructions. This means these instructions must be indexed, as zero in that area is used to indicate instructions of a different kind.
Thus, a table entry is at the location indicated by the address formed by the contents of the displacement field plus the contents of base register zero; the first 64 bits of the table entry is added to the contents of the index register indicated to form the effective address of the data used, but the contents of the index register must be, considered as an unsigned quantity, less than or equal to the bound given in the second 64 bits of the table entry (thus, unless that bound is all ones, there is also a lower bound of zero).
Also, space was found for a Load Address instruction; while the Load Base with Address instruction has a sufficient destination register field for its purposes, the Load Address instruction is restricted to integer registers 0 to 7. As well, even unaligned load and store instructions are available, but only registers 0 and 1 can be their destination registers, and if they are indexed, they can only be indexed by integer register 1. However, a five-bit opcode field is still present, so for the shorter integer types, unaligned Unsigned Load and Insert are available.